Анализ многомерный статистический. Введение в многомерный статистический анализ - калинина Оценивание линейной прогностической функции
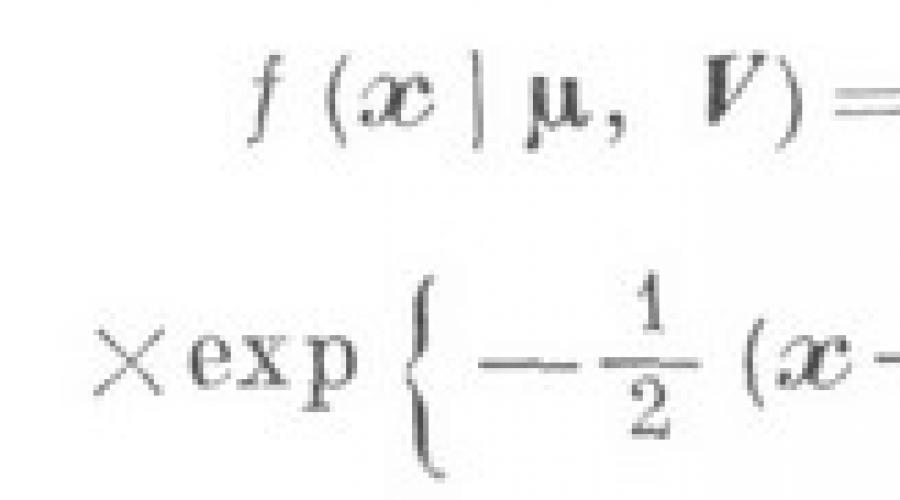
Читайте также
Встречаются такие ситуации, в которых случайная изменчивость была представлена одной-двумя случайными переменными, признаками.
Например, при исследовании статистической совокупности людей нас интересуют рост и вес. В этой ситуации, сколько бы людей в статистической совокупности ни было, мы всегда можем построить диаграмму рассеяния и увидеть всю картину в целом. Однако если признаков три, например, добавляется признак - возраст человека, тогда диаграмма рассеяния должна быть построена в трехмерном пространстве. Представить совокупность точек в трехмерном пространстве уже довольно затруднительно.
В реальности на практике каждое наблюдение представляется не одним-двумя-тремя числами, а некоторым заметным набором чисел, которые описывают десятки признаков. В этой ситуации для построения диаграммы рассеяния потребовалось бы рассматривать многомерные пространства.
Раздел статистики, посвященный исследованиям экспериментов с многомерными наблюдениями, называется многомерным статистическим анализом.
Измерение сразу нескольких признаков (свойств объекта) в одном эксперименте в общем более естественно, чем измерение какого-либо одного, двух. Поэтому потенциально многомерный статистический анализ имеет широкое поле для применения.
К многомерному статистическому анализу относят следующие разделы:
Факторный анализ;
Дискриминантный анализ;
Кластерный анализ;
Многомерное шкалирование;
Методы контроля качества.
Факторный анализ
При исследовании сложных объектов и систем (например, в психологии, биологии, социологии и т. д.) величины (факторы), определяющие свойства этих объектов, очень часто невозможно измерить непосредственно, а иногда неизвестно даже их число и содержательный смысл. Но для измерения могут быть доступны иные величины, так или иначе зависящие от интересующих факторов. При этом когда влияние неизвестного интересующего нас фактора проявляется в нескольких измеряемых признаках, эти признаки могут обнаруживать тесную связь между собой и общее число факторов может быть гораздо меньше, чем число измеряемых переменных.
Для обнаружения факторов, влияющих на измеряемые переменные, используются методы факторного анализа.
Примером применения факторного анализа может служить изучение свойств личности на основе психологических тестов. Свойства личности не поддаются прямому измерению, о них можно судить только по поведению человека или характеру ответов на те или иные вопросы. Для объяснения результатов опытов их подвергают факторному анализу, который и позволяет выявить те личностные свойства, которые оказывают влияние на поведение испытуемых индивидуумов.
В основе различных моделей факторного анализа лежит следующая гипотеза: наблюдаемые или измеряемые параметры являются лишь косвенными характеристиками изучаемого объекта или явления, в действительности существуют внутренние (скрытые, латентные, не наблюдаемые непосредственно) параметры и свойства, число которых мало и которые определяют значения наблюдаемых параметров. Эти внутренние параметры принято называть факторами.
Задачей факторного анализа является представление наблюдаемых параметров в виде линейных комбинаций факторов и, быть может, некоторых дополнительных, несущественных возмущений.
Первый этап факторного анализа, как правило, – это выбор новых признаков, которые являются линейными комбинациями прежних и «вбирают» в себя большую часть общей изменчивости наблюдаемых данных, а потому передают большую часть информации, заключенной в первоначальных наблюдениях. Обычно это осуществляется с помощью метода главных компонент, хотя иногда используют и другие приемы (метод максимального правдоподобия).
Метод главных компонент сводится к выбору новой ортогональной системы координат в пространстве наблюдений. В качестве первой главной компоненты избирают направление, вдоль которого массив наблюдений имеет наибольший разброс, выбор каждой последующей главной компоненты происходит так, чтобы разброс наблюдений был максимальным и чтобы эта главная компонента была ортогональна другим главным компонентам, выбранным ранее. Однако факторы, полученные методом главных компонент, обычно не поддаются достаточно наглядной интерпретации. Поэтому следующий шаг факторного анализа - преобразование, вращение факторов для облегчения интерпретации.
Дискриминантный анализ
Пусть имеется совокупность объектов, разбитая на несколько групп, и для каждого объекта можно определить, к какой группе он относится. Для каждого объекта имеются измерения нескольких количественных характеристик. Необходимо найти способ, как на основании этих характеристик можно узнать группу, к которой относится объект. Это позволит указывать группы, к которым относятся новые объекты той же совокупности. Для решения поставленной задачи применяются методы дискриминантного анализа.
Дискриминантный анализ - это раздел статистики, содержанием которого является разработка методов решения задач различения (дискриминации) объектов наблюдения по определенным признакам.
Рассмотрим некоторые примеры.
Дискриминантный анализ оказывается удобным при обработке результатов тестирования отдельных лиц, когда дело касается приема на ту или иную должность. В этом случае необходимо всех кандидатов разделить на две группы: «подходит» и «не подходит».
Использование дискриминантного анализа возможно банковской администрацией для оценки финансового состояния дел клиентов при выдаче им кредита. Банк по ряду признаков классифицирует их на надежных и ненадежных.
Дискриминантный анализ может быть привлечен в качестве метода разбиения совокупности предприятий на несколько однородных групп по значениям каких-либо показателей производственно-хозяйственной деятельности.
Методы дискриминантного анализа позволяют строить функции измеряемых характеристик, значения которых и объясняют разбиение объектов на группы. Желательно, чтобы этих функций (дискриминантных признаков) было немного. В этом случае результаты анализа легче содержательно толковать.
Благодаря своей простоте особую роль играет линейный дискриминантный анализ, в котором классифицирующие признаки выбираются как линейные функции от первичных признаков.
Кластерный анализ
Методы кластерного анализа позволяют разбить изучаемую совокупность объектов на группы «схожих» объектов, называемых кластерами.
Слово кластер английского происхождения - cluster переводится как кисть, пучок, группа, рой, скопление.
Кластерный анализ решает следующие задачи:
Проводит классификацию объектов с учетом всех тех признаков, которые характеризуют объект. Сама возможность классификации продвигает нас к более углубленному пониманию рассматриваемой совокупности и объектов, входящих в нее;
Ставит задачу проверки наличия априорно заданной структуры или классификации в имеющейся совокупности. Такая проверка дает возможность воспользоваться стандартной гипотетико-дедуктивной схемой научных исследований.
Большинство методов кластеризации (иерархической группы) являются агломеративными (объединительными) - они начинают с создания элементарных кластеров, каждый из которых состоит ровно из одного исходного наблюдения (одной точки), а на каждом последующем шаге происходит объединение двух наиболее близких кластеров в один.
Момент остановки этого процесса может задаваться исследователем (например, указанием требуемого числа кластеров или максимального расстояния, при котором достигнуто объединение).
Графическое изображение процесса объединения кластеров может быть получено с помощью дендрограммы - дерева объединения кластеров.
Рассмотрим следующий пример. Проведем классификацию пяти предприятий, каждое из которых характеризуется тремя переменными:
х 1 – среднегодовая стоимость основных производственных фондов, млрд руб.;
х 2 – материальные затраты на 1 руб. произведенной продукции, коп.;
х 3 – объем произведенной продукции, млрд руб.
Внедрение ПЭВМ в управление народным хозяйством предполагает переход от традиционных методов анализа деятельности предприятий в более совершенных моделей управления экономикой, которые позволяют раскрыть ее глубинные процессы.
Широкое использование в экономических исследованиях методов математической статистики дает возможность углубить экономический анализ, повысить качество информации в планировании и прогнозировании показателей производства и анализа его эффективности.
Сложность и разнообразие связей экономических показателей обусловливают многомерность признаков и в связи с этим требуют применения наиболее сложного математического аппарата - методов многомерного статистического анализа.
Понятие "многомерный статистический анализ" подразумевает объединение ряда методов, призванных исследовать сочетание взаимосвязанных признаков. Речь идет о расчленении (разбиение) рассматриваемой совокупности, которая представлена многомерными признаками на относительно небольшую их количество.
При этом переход от большого количества признаков к меньшей преследует цель снижения их размерности и повышения информативной емкости. Такая цель достигается путем выявления информации, повторяется, порождаемой взаимосвязанными признаками, установлением возможности агрегирования (объединения, суммирование) по некоторым признакам. Последнее предполагает превращение фактической модели в модель с меньшим количеством факторных признаков.
Метод многомерного статистического анализа позволяет выявлять объективно существующие, но явно не выражены закономерности, которые проявляются в тех или иных социально - экономических явлениях. С этим приходится сталкиваться при решении ряда практических задач в области экономики. В частности, сказанное имеет место, если необходимо накапливать (фиксировать) одновременно значения нескольких количественных характеристик (признаков) по изучаемому объекту наблюдения, когда каждая характеристика склонна к неконтролируемой вариации (в разрезе объектов), несмотря на однородность объектов наблюдения.
Например, исследуя однородные (по природно-экономическими условиями и типом специализации) предприятия по ряду показателей эффективности производства, убеждаемся, что при переходе от одного объекта к другому почти каждый из отобранных характеристик (идентичных) имеет неодинаковое числовое значение, то есть находит так сказать неконтролируемый (случайный) разброс. Такое "случайное" варьирования признаков, как правило, подчиняется некоторым (закономерным) тенденциям как в плане достаточно определенных размеров признаков, вокруг которых осуществляется вариация, так и в плане степени и взаимозависимости самого варьирования.
Сказанное выше приводит к определению многомерной случайной величины как набора количественных признаков, значение каждой из которых подвергается неконтролируемом разброса при повторениях данного процесса, статистического наблюдения, опыта, эксперимента и др.
Ранее было сказано, что многомерный анализ объединяет ряд методов; назовем их: факторный анализ, метод главных компонент, кластерный анализ, распознавание образов, дискриминантный анализ и и др. Первые три из названных методов рассматриваться в следующих параграфах.
Как и другие математико - статистические методы, многомерный анализ может быть эффективным в своем применении при условии высокого качества исходной информации и массовости данных наблюдений, обрабатываются с помощью ПЭВМ.
Основные понятия метода факторного анализа, суть решаемых им задач
При анализе (в равной степени и исследованы) социально - экономических явлений приходится часто встречаться со случаями, когда среди разнообразия (багатопараметричности) объектов наблюдения необходимо исключать долю параметров, или заменить их меньшим количеством тех или других функций, не причинив вреда целостности (полноте) информации. Решение такой задачи имеет смысл в рамках определенной модели и обусловлено ее структурой. Примером такой модели, которая наиболее подходит ко многим реальным ситуациям, является модель факторного анализа, методы которого позволяют сконцентрировать признаки (информацию о них) путем "конденсации" большого числа в меньше, информационное более емкое. При этом полученный "конденсат" информации должен быть представлен наиболее существенными и определяющими количественными характеристиками.
Понятие "факторный анализ" не надо смешивать с широким понятием анализа причинно - следственных связей, когда изучается влияние различных факторов (их сочетаний, комбинаций) на результативный признак.
Суть метода факторного анализа заключается в исключении описания множественных характеристик изучаемых и замене его меньшим количеством информационно более емких переменных, которые называются факторами и отражают наиболее существенные свойства явлений. Такие переменные являются некоторыми функциями исходных признаков.
Анализ, по словам Я. Окуня 9, позволяет иметь первые приближенные характеристики закономерностей, лежащих в основе явления, сформулировать первые, общие выводы о направлениях, в которых нужно вести дальнейшее исследование. Далее он указывает на основное предположение факторного анализа, которое сводиться к тому, что явление, несмотря на свою разнородность и изменчивость можно описывать небольшим количеством функциональных единиц, параметров или факторов. Эти сроки называют по - разному: влияние, причины, параметры, функциональные единицы, способности, основные или независимые показатели. Использование того или иного срока обусловлено
Окунь Я. Факторный анализ: Пер. с. пол. М.: Статистика, 1974.- С.16.
контекстом о факторе и знанием сути изучаемого явления.
Этапами факторного анализа являются последовательные сопоставления различных наборов факторов и вариантов группам с их включением, выключением и оценкой достоверности различий между группами.
В.М.Жуковська и И.Б.Мучник 10, говоря о сути задач факторного анализа, утверждают, что последний не требует априорного подразделения переменных на зависимые и независимые, поскольку все переменные в нем рассматриваются как равноправные.
Задача факторного анализа сводится к определенному понятию, числа и природы наиболее существенных и относительно независимых функциональных характеристик явления, его измерителей или базовых параметров - факторов. По мнению авторов, важной отличительной особенностью факторного анализа является то, что он позволяет одновременно исследовать большое число взаимосвязанных переменных без допущения о "неизменности всех других условий", так необходимого при использовании ряда других методов анализа. В этом большое преимущество факторного анализа как ценного инструмента исследования явления, обусловленного сложной разнообразием и взаемопереплетенням связей.
Анализ опирается в основном на наблюдения над естественным варьированием переменных.
1. При использовании факторного анализа совокупность переменных, которые изучаются с точки зрения связей между ними, не выбирается произвольно: этот метод позволяет выявлять основные факторы, которые осуществляют существенное влияние в данной области.
2. Анализ не требует предварительных гипотез, наоборот, он сам может служить методом выдвижения гипотез, а также выступать критерием гипотез, опирающихся на данные, полученные другими методами.
3. Анализ не требует априорных догадок относительно того, какие переменные независимы, а зависимые, он не гипертрофирует причинные связи и решает вопрос об их мере в процессе дальнейших исследований.
Перечень конкретных задач, решаемых с использованием методов факторного анализа будет таким (по В.М.Жуковською). Назовем основные из них в области социально-экономических исследований:
Жуковская В.М., Мучник И.Б. Факторный анализ в социально-Экономическим исследованиях. -Статистика, 1976. С.4.
1. Определение основных аспектов различий между объектами наблюдения (минимизация описание).
2. Формулировка гипотез о природе различий между объектами.
3. Выявление структуры взаимосвязей между признаками.
4. Проверка гипотез о взаимосвязи и взаимозаменяемости признаков.
5. Сопоставление структур наборов признаков.
6. Расчленение объектов наблюдения за типичными признаками.
Изложенное свидетельствует о больших возможностях факторного анализа в
исследовании общественных явлений, где, как правило, невозможно проконтролировать (экспериментально) влияние отдельных факторов.
Достаточно эффективным является использование результатов факторного анализа в моделях множественной регрессии.
Имея предварительно сформированную корреляционно-регрессионную модель изучаемого явления в виде коррелированных признаков, с помощью факторного анализа можно такой набор признаков превратить в значительно меньшую их количество путем агрегирования. При этом следует отметить, что такое преобразование ни в коей мере не ухудшает качество и полноту информации об изучаемом явлении. Созданные агрегированные признаки некоррелированы и представляют линейную комбинацию первичных признаков. С формальной математической стороны постановка задач в таком случае может иметь бесконечную множественную решений. Но нужно помнить, что при изучении социально - экономических явлений полученные агрегированные признаки должны иметь экономически обоснованное трактовки. Иначе говоря, в каком - либо случае использования математического аппарата в первую очередь выходят из знаний экономической сути изучаемых явлений.
Таким образом, сказанное выше позволяет резюмировать, что факторный анализ является специфическим методом исследования, который осуществляется на базе арсенала приемов математической статистики.
Свое практическое применение факторный анализ впервые нашел в области психологии. Возможность свести большое количество психологических тестов к небольшому количеству факторов позволило объяснить способности человеческого интеллекта.
При исследовании социально-экономических явлений, где есть трудности в изолировании влияния отдельных переменных, успешно может быть использован факторный анализ. Применение его приемов позволяет путем определенных расчетов "профильтровать" несущественные признаки и продолжить исследования в направлении его углубления.
Эффективность этого метода очевидна при исследовании таких вопросов (проблем): в экономике - специализация и концентрация производства, интенсивность ведения хозяйства, бюджет семей работников, построение различных обобщающих показателей. и т.д
МНОГОМЕРНЫЙ СТАТИСТИЧЕСКИЙ АНАЛИЗ
Раздел математич. статистики, посвященный математич. методам построения оптимальных планов сбора, систематизации и обработки многомерных статистич. данных, направленным на выявление характера и структуры взаимосвязей между компонентами исследуемого многомерного признака и предназначенным для получения научных и практич. выводов. Под многомерным признаком понимается р-мерный показателей (признаков, переменных) среди к-рых могут быть: количественные, т. е. скалярно измеряющие в определенной шкале проявления изучаемого свойства объекта, п о-рядковые (или ординальные), т. е. позволяющие упорядочивать анализируемые объекты по степени проявления в них изучаемого свойства; и классификационные (или номинальные), т. е. позволяющие разбивать исследуемую совокупность объектов на не поддающиеся упорядочиванию однородные (по анализируемому свойству) классы. Результаты измерения этих показателей
на каждом из побъектов исследуемой совокупности образуют многомерных наблюдений, или исходный массив многомерных данных для проведения М. с. а. Значительная часть М. с. а. обслуживает ситуации, в к-рых исследуемый многомерный признак интерпретируется как многомерная и соответственно последовательность многомерных наблюдений (1) - как из генеральной совокупности. В этом случае выбор методов обработки исходных статистич. данных и анализ их свойств производится на основе тех или иных допущений относительно природы многомерного (совместного) закона распределения вероятностей
Многомерный статистический анализ многомерных распределений и их основных характеристик охватывает лишь ситуации, в к-рых обрабатываемые наблюдения (1) имеют вероятностную природу, т. е. интерпретируются как выборка из соответствующей генеральной совокупности. К основным задачам этого подраздела относятся: статистич. оценивание исследуемых многомерных распределений, их основных числовых характеристик и параметров; исследование свойств используемых статистич. оценок; исследование распределений вероятностей для ряда статистик, с помощью к-рых строятся статистич. критерии проверки различных гипотез о вероятностной природе анализируемых многомерных данных. Основные результаты относятся к частному случаю, когда исследуемый признак подчинен многомерному нормальному закону распределения функция плотности к-рого задается соотношением

где - вектор математич. ожиданий компонент случайной величины , т. е.![]() - ковариационная матрица случайного вектора , т. е.- ковариации компонент вектора (рассматривается невырожденный случай, когда ; в противном случае, т. е. при ранге , все результаты остаются справедливыми, но применительно к подпространству меньшей размерности , в к-рой оказывается сосредоточенным исследуемого случайного вектора ).
- ковариационная матрица случайного вектора , т. е.- ковариации компонент вектора (рассматривается невырожденный случай, когда ; в противном случае, т. е. при ранге , все результаты остаются справедливыми, но применительно к подпространству меньшей размерности , в к-рой оказывается сосредоточенным исследуемого случайного вектора ).
Так, если (1) - последовательность независимых наблюдений, образующих случайную выборку из то оценками максимального правдоподобия для параметров и , участвующих в (2), являются соответственно статистики (см. , )
причем случайный вектор подчиняется р-мерному нормальному закону ![]() и не зависит от , а совместное распределение элементов матрицы описывается т. н. распределением Уиша р-т а (см. ), к-рого
и не зависит от , а совместное распределение элементов матрицы описывается т. н. распределением Уиша р-т а (см. ), к-рого

В рамках этой же схемы исследованы распределения и моменты таких выборочных характеристик многомерной случайной величины, как коэффициенты парной, частной и множественной корреляции, обобщенная (т. е. ), обобщенная -статистике Хотеллинга (см. ). В частности (см. ), если определить в качестве выборочной ковариационной матрицы подправленную "на несмещенность" оценку , а именно:
то случайной величины ![]() стремится к при , а случайные величины
стремится к при , а случайные величины

подчиняются F-распределениям с числами степеней свободы соответственно (р, п-р) и (р, п 1 +п 2 -р-1). В соотношении (7) п 1 и n 2 - объемы двух независимых выборок вида (1), извлеченных из одной и той же генеральной совокупности - оценки вида (3) и (4)-(5), построенные по i-й выборке, а
Общая выборочная ковариационная , построенная по оценкам и
Многомерный статистический анализ характера и структуры взаимосвязей компонент исследуемого многомерного признака объединяет в себе понятия и результаты, обслуживающие такие методы и модели М. с. а., как множественная , многомерный дисперсионный анализ и ковариационный анализ, факторный анализ и метод главных компонент, анализ канонич. корреляций. Результаты, составляющие содержание этого подраздела, могут быть условно разделены на два основных типа.
1) Построение наилучших (в определенном смысле) статистич. оценок для параметров упомянутых моделей и анализ их свойств (точности, а в вероятностной постановке - законов их распределения, доверительных: областей и т. д.). Так, пусть исследуемый многомерный признак интерпретируется как векторная случайная , подчиненная р-мерному нормальному распределению , и расчленен на два подвектора--столбца и размерности qи р-qсоответственно. Это определяет и соответствующее расчленение вектора математич. ожиданий , теоретической и выборочной ковариационных матриц , а именно:
Тогда (см. , ) подвектора (при условии, что второй подвектор принял фиксированное значение ) будет также нормальным ). При этом оценками максимального правдоподобия. для матриц регрессионных коэффициентов и ковариацин этой классической многомерной модели множественной регрессии
будут взаимно независимые статистики соответственно
здесь распределение оценки подчинено нормальному закону ![]() , а оценки п - закону Уишарта с параметрами и (элементы ковариационной матрицы выражаются в терминах элементов матрицы ).
, а оценки п - закону Уишарта с параметрами и (элементы ковариационной матрицы выражаются в терминах элементов матрицы ).
Основные результаты по построению оценок параметров и исследованию их свойств в моделях факторного" анализа, главных компонент и канонич. корреляций относятся к анализу вероятностно-статистич. свойств собственных (характеристических) значений и векторов различных выборочных ковариационных матриц.
В схемах, не укладывающихся в рамки классич. нормальной модели и тем более в рамки какой-либо вероятностной модели, основные результаты относятся к построению алгоритмов (и исследованию их свойств) вычисления оценок параметров, наилучших с точки зрения нек-poro экзогенно заданного функционала качества (пли адекватности) модели.
2) Построение статистич. критериев для проверки различных гипотез о структуре исследуемых взаимосвязей. В рамках многомерной нормальной модели (последовательности наблюдений вида (1) интерпретируются как случайные выборки из соответствующих многомерных нормальных генеральных совокупностей) построены, напр., статистич. критерии для проверки следующих гипотез.
I. Гипотезы о равенстве вектора математич. ожиданий исследуемых показателей заданному конкретному вектору ; проверяется с помощью -статистики Хотеллинга с подстановкой в формулу (6)
II. Гипотезы о равенстве векторов математич. ожиданий в двух генеральных совокупностях (с одинаковыми, но неизвестными ковариационными матрицами), представленных двумя выборками; проверяется с помощью статистики (см. ).
III. Гипотезы о равенстве векторов математич. ожиданий в нескольких генеральных совокупностях (с одинаковыми, но неизвестными ковариационными матрицами), представленных своими выборками; проверяется с помощью статистики
в к-рой есть i-е р-мерное наблюдение в выборке объема , представляющей j-ю генеральную совокупность, а и - оценки вида (3), построенные соответственно отдельно по каждой из выборок и по объединенной выборке объема
IV. Гипотезы об эквивалентности нескольких нормальных генеральных совокупностей, представленных своими выборками проверяется с помощью статистики

в к-рой - оценка вида (4), построенная отдельно по наблюдениям j- йвыборки, j=1, 2, ... , k.
V. Гипотезы о взаимной независимости подвекторов-столбцов размерностей соответственно на к-рые расчленен исходный р-мерный вектор исследуемых показателей проверяется с помощью статистики

в к-рой и - выборочные ковариационные матрицы вида (4) для всего вектора и для его подвектора x (i) соответственно.
Многомерный статистический анализ геометрической структуры исследуемой совокупности многомерных наблюдений объединяет в себе понятия и результаты таких моделей и схем, как дискриминантный анализ, смеси вероятностных распределений, кластер-анализ и таксономия, многомерное шкалирование. Узловым во всех этих схемах является понятие расстояния (меры близости, меры сходства) между анализируемыми элементами. При этом анализируемыми могут быть как реальные объекты, на каждом из к-рых фиксируются значения показателей ,- тогда геометрич. образом i-го обследованного объекта будет точка в соответствующем р-мерном пространстве, так и сами показатели - тогда геометрич. образом l-го показателя будет точка в соответствующем n-мерном пространстве.
Методы и результаты дискриминантного анализа (см. , , ) направлены на следующей задачи. Известно о существовании определенного числа генеральных совокупностей и у исследователя имеется по одной выборке из каждой совокупности ("обучающие выборки"). Требуется построить основанное на имеющихся обучающих выборках наилучшее в определенном смысле классифицирующее правило, позволяющее приписать нек-рый новый элемент (наблюдение ) к своей генеральной совокупности в ситуации, когда исследователю заранее не известно, к какой из совокупностей этот элемент принадлежит. Обычно под классифицирующим правилом понимается последовательность действий: по вычислению скалярной функции от исследуемых показателей, по значениям к-рой принимается решение об отнесении элемента к одному из классов (построение дискриминантной функции); по упорядочению самих показателей по степени их информативности с точки зрения правильного отнесения элементов к классам; по вычислению соответствующих вероятностей ошибочной классификации.
Задача анализа смесей распределений вероятностей (см. ) чаще всего (но не всегда) возникает также в связи с исследованием "геометрической структуры" рассматриваемой совокупности. При этом понятие r-го однородного класса формализуется с помощью генеральной совокупности, описываемой нек-рым (как правило, унимодальным) законом распределения так что распределение общей генеральной совокупности, из к-рой извлечена выборка (1), описывается смесью распределений вида где p r - априорная вероятность (удельный элементов) r-го класса в общей генеральной совокупности. Задача состоит в "хорошем" статистич. оценивании (по выборке ) неизвестных параметров а иногда и к. Это, в частности, позволяет свести задачу классификации элементов к схеме дискриминантного анализа, хотя в данном случае отсутствовали обучающие выборки.
Методы и результаты кластер-анализа (классификации, таксономии, распознавании образов "без учителя", см. , , ) направлены на решение следующей задачи. Геометрич. анализируемой совокупности элементов задана либо координатами соответствующих точек (т. е. матрицей ... , п), либо набором геометрич. характеристик их взаимного расположения, напр, матрицей попарных расстояний . Требуется разбить исследуемую совокупность элементов на сравнительно небольшое (заранее известное или нет) классов так, чтобы элементы одного класса находились на небольшом расстоянии друг от друга, в то время как разные классы были бы по возможности достаточно взаимоудалены один от другого и не разбивались бы на столь же удаленные друг от друга части.
Задача многомерного шкалирования (см. ) относится к ситуации, когда исследуемая совокупность элементов задана с помощью матрицы попарных расстояний и заключается в приписывании каждому из элементов заданного числа (р)координат таким образом, чтобы структура попарных взаимных расстояний между элементами, измеренных с помощью этих вспомогательных координат, в среднем наименее отличались бы от заданной. Следует заметить, что основные результаты и методы кластер-анализа и многомерного шкалирования развиваются обычно без каких-либо допущении о вероятностной природе исходных данных.
Прикладное назначение многомерного статистического анализа состоит в основном в обслуживании следующих трех проблем.
Проблема статистического исследования зависимостей между анализируемыми показателями. Предполагая, что исследуемый набор статистически регистрируемых показателей xразбит, исходя из содержательного смысла этих показателей и окончательных целей исследования, на q-мернын подвектор предсказываемых (зависимых) переменных и (р-q)-мерный подвектор предсказывающих (независимых) переменных, можно сказать, что проблема состоит в определении на основании выборки (1) такой q-мерной векторной функции из класса допустимых решений F, к-рая давала бы наилучшую, в определенном смысле, аппроксимацию поведения подвектора показателей . В зависимости от конкретного вида функционала качества аппроксимации и природы,анализируемых показателей приходят к тем или иным схемам множественной регрессии, дисперсионного, ковариационного или конфлюентного анализа.
Проблема классификации элементов (объектов или показателей) в общей (нестрогой) постановке заключается в том, чтобы всю анализируемую совокупность элементов, статистически представленную в виде матрицы или матрицы разбить на сравнительно небольшое число однородных, в определенном смысле, групп . В зависимости от природы априорной информации и конкретного вида функционала, задающего критерий качества классификации, приходят к тем или иным схемам дискриминантного анализа, кластер-анализа (таксономии, распознавания образов "без учителя"), расщепления смесей распределений.
Проблема снижения размерности исследуемого факторного пространства и отбора наиболее информативных показателей заключается в определении такого набора сравнительно небольшого числа показателен найденного в классе допустимых преобразований исходных показателей ![]() на к-ром достигается верхняя нек-рой экзогенно заданной меры информативности m-мерной системы признаков (см. ). Конкретизация функционала, задающего меру автоинформативности (т. е. нацеленное на максимальное сохранение информации, содержащейся в статистич. массиве (1) относительно самих исходных признаков), приводит, в частности, к различным схемам факторного анализа и главных компонент, к методам экстремальной группировки признаков. Функционалы, задающие меру внешней информативности, т. е. нацеленные на извлечение из (1) максимальной информации относительно нек-рых других, не содержащихся непосредственно в ж, показателен или явлений, приводят к различным методам отбора наиболее информативных показателей в схемах статистич. исследования зависимостей и дискриминантного анализа.
на к-ром достигается верхняя нек-рой экзогенно заданной меры информативности m-мерной системы признаков (см. ). Конкретизация функционала, задающего меру автоинформативности (т. е. нацеленное на максимальное сохранение информации, содержащейся в статистич. массиве (1) относительно самих исходных признаков), приводит, в частности, к различным схемам факторного анализа и главных компонент, к методам экстремальной группировки признаков. Функционалы, задающие меру внешней информативности, т. е. нацеленные на извлечение из (1) максимальной информации относительно нек-рых других, не содержащихся непосредственно в ж, показателен или явлений, приводят к различным методам отбора наиболее информативных показателей в схемах статистич. исследования зависимостей и дискриминантного анализа.
Основной математический инструментарий М. с. а. составляют специальные методы теории систем линейных уравнений и теории матриц (методы решения простой и обобщенной задачи о собственных значениях и векторах; простое обращение и псевдообращение матриц; процедуры диагонализации матриц и т. д.) и нек-рые оптимизационные алгоритмы (методы покоординатного спуска, сопряженных градиентов, ветвей и границ, различные версии случайного поиска и стохастич. аппроксимации и т. д.).
Лит. : Андерсон Т., Введение в многомерный статистический анализ, пер. с англ., М., 1963; Кендалл М. Дж.., Стьюарт А., Многомерный статистический анализ и временные ряды, пер. с англ., М., 1976; Большев Л. Н., "Bull. Int. Stat. Inst.", 1969, № 43, p. 425-41; Wishаrt .J., "Biometrika", 1928, v. 20A, p. 32-52: Hotelling H., "Ann. Math. Stat.", 1931, v. 2, p. 360-78; [в] Кruskal J. В., "Psychometrika", 1964, v. 29, p. 1-27; Айвазян С. А., Бежаева 3. И., . Староверов О. В., Классификация многомерных наблюдений, М., 1974.
С. А. Айвазян.
Математическая энциклопедия. - М.: Советская энциклопедия . И. М. Виноградов . 1977-1985 .
Справочник технического переводчикаРаздел статистики математической (см.), посвященный математич. методам, направленным на выявление характера и структуры взаимосвязей между компонентами исследуемого многомерного признака (см.) и предназначенным для получения научн. и практич.… …
В широком смысле раздел математической статистики (См. Математическая статистика), объединяющий методы изучения статистических данных, относящихся к объектам, которые характеризуются несколькими качественными или количественными… … Большая советская энциклопедия
АНАЛИЗ МНОГОМЕРНЫЙ СТАТИСТИЧЕСКИЙ - раздел математической статистики, предназначенный для анализа связей между тремя и более переменными. Можно условно выделить три основных класса задач А.М.С. Это исследование структуры связей между переменными и снижение размерности пространства … Социология: Энциклопедия
АНАЛИЗ КОВАРИАЦИОННЫЙ - – совокупность методов математич. статистики, относящихся к анализу моделей зависимости среднего значения нек рой случайной величины Y от набора неколичественных факторов F и одновременно от набора количественных факторов X. По отношению к Y… … Российская социологическая энциклопедия
Раздел математич. статистики, содержанием к рого является разработка и исследование статистич. методов решения следующей задачи различения (дискриминации): основываясь на результатах наблюдений, определить, какой из нескольких возможных… … Математическая энциклопедия, Орлова Ирина Владленовна, Концевая Наталья Валерьевна, Турундаевский Виктор Борисович. Книга посвящена многомерному статистическому анализу (МСА) и организации вычислений по МСА. Для реализации методов многомерной статистики используется программаобработки статистической…
Многомерный статистический анализ применяют при решении следующих задач:
- * исследование зависимости между признаками;
- * классификация объектов или признаков, заданных векторами;
- * снижение размерности пространства признаков.
При этом результат наблюдений - вектор значений фиксированного числа количественных и иногда качественных признаков, измеренных у объекта. Количественный признак - признак наблюдаемой единицы, который можно непосредственно выразить числом и единицей измерения. Количественный признак противопоставляется качественному - признаку наблюдаемой единицы, определяемому отнесением к одной из двух или более условных категорий (если имеется ровно две категории, то признак называется альтернативным). Статистический анализ качественных признаков - часть статистики объектов нечисловой природы. Количественные признаки делятся на признаки, измеренные в шкалах интервалов, отношений, разностей, абсолютной.
А качественные - на признаки, измеренные в шкале наименований и порядковой шкале. Методы обработки данных должны быть согласованы со шкалами, в которых измерены рассматриваемые признаки.
Целями исследования зависимости между признаками являются доказательство наличия связи между признаками и изучение этой связи. Для доказательства наличия связи между двумя случайными величинами Х и У применяют корреляционный анализ. Если совместное распределение Х и У является нормальным, то статистические выводы основывают на выборочном коэффициенте линейной корреляции, в остальных случаях используют коэффициенты ранговой корреляции Кендалла и Спирмена, а для качественных признаков - критерий хи-квадрат.
Регрессионный анализ применяют для изучения функциональной зависимости количественного признака У от количественных признаков x(1), x(2), … , x(k). Эту зависимость называют регрессионной или, кратко, регрессией. Простейшая вероятностная модель регрессионного анализа (в случае k = 1) использует в качестве исходной информации набор пар результатов наблюдений (xi, yi), i = 1, 2, … , n, и имеет вид
yi = axi + b + еi, i = 1, 2, … , n,
где еi - ошибки наблюдений. Иногда предполагают, что еi - независимые случайные величины с одним и тем же нормальным распределением N(0, у2). Поскольку распределение ошибок наблюдения обычно отлично от нормального, то целесообразно рассматривать регрессионную модель в непараметрической постановке, т.е. при произвольном распределении еi.
Основная задача регрессионного анализа состоит в оценке неизвестных параметров а и b, задающих линейную зависимость y от x. Для решения этой задачи применяют разработанный еще К.Гауссом в 1794 г. метод наименьших квадратов, т.е. находят оценки неизвестных параметров моделиa и b из условия минимизации суммы квадратов
по переменным а и b.
Дисперсионный анализ применяют для изучения влияния качественных признаков на количественную переменную. Например, пусть имеются k выборок результатов измерений количественного показателя качества единиц продукции, выпущенных на k станках, т.е. набор чисел (x1(j), x2(j), … , xn(j)), где j - номер станка, j = 1, 2, …, k, а n - объем выборки. В распространенной постановке дисперсионного анализа предполагают, что результаты измерений независимы и в каждой выборке имеют нормальное распределение N(m(j), у2) с одной и той же дисперсией.
Проверка однородности качества продукции, т.е. отсутствия влияния номера станка на качество продукции, сводится к проверке гипотезы
H0: m(1) = m(2) = … = m(k).
В дисперсионном анализе разработаны методы проверки подобных гипотез.
Гипотезу Н0 проверяют против альтернативной гипотезы Н1, согласно которой хотя бы одно из указанных равенств не выполнено. Проверка этой гипотезы основана на следующем «разложении дисперсий», указанном Р.А.Фишером:
где s2 - выборочная дисперсия в объединенной выборке, т.е.
Таким образом, первое слагаемое в правой части формулы (7) отражает внутригрупповую дисперсию. Наконец, - межгрупповая дисперсия,
Область прикладной статистики, связанную с разложениями дисперсии типа формулы (7), называют дисперсионным анализом. В качестве примера задачи дисперсионного анализа рассмотрим проверку приведенной выше гипотезы Н0 в предположении, что результаты измерений независимы и в каждой выборке имеют нормальное распределение N(m(j), у2) с одной и той же дисперсией. При справедливости Н0 первое слагаемое в правой части формулы (7), деленное на у2, имеет распределение хи-квадрат с k(n-1) степенями свободы, а второе слагаемое, деленное на у2, также имеет распределение хи-квадрат, но с (k-1) степенями свободы, причем первое и второе слагаемые независимы как случайные величины. Поэтому случайная величина

имеет распределение Фишера с (k-1) степенями свободы числителя и k(n-1) степенями свободы знаменателя. Гипотеза Н0 принимается, если F < F1-б, и отвергается в противном случае, где F1-б - квантиль порядка 1-б распределения Фишера с указанными числами степеней свободы. Такой выбор критической области определяется тем, что при Н1 величина F безгранично увеличивается при росте объема выборок n. Значения F1-б берут из соответствующих таблиц.
Разработаны непараметрические методы решения классических задач дисперсионного анализа, в частности, проверки гипотезы Н0.
Следующий тип задач многомерного статистического анализа - задачи классификации. Они делятся на три принципиально различных вида - дискриминантный анализ, кластер-анализ, задачи группировки.
Задача дискриминантного анализа состоит в нахождении правила отнесения наблюдаемого объекта к одному из ранее описанных классов. При этом объекты описывают в математической модели с помощью векторов, координаты которых - результаты наблюдения ряда признаков у каждого объекта. Классы описывают либо непосредственно в математических терминах, либо с помощью обучающих выборок. Обучающая выборка - это выборка, для каждого элемента которой указано, к какому классу он относится.
Рассмотрим пример применения дискриминантного анализа для принятия решений в технической диагностике. Пусть по результатам измерения ряда параметров продукции необходимо установить наличие или отсутствие дефектов. В этом случае для элементов обучающей выборки указаны дефекты, обнаруженные в ходе дополнительного исследования, например, проведенного после определенного периода эксплуатации. Дискриминантный анализ позволяет сократить объем контроля, а также предсказать будущее поведение продукции. Дискриминантный анализ сходен с регрессионным - первый позволяет предсказывать значение качественного признака, а второй - количественного. В статистике объектов нечисловой природы разработана математическая схема, частными случаями которой являются регрессионный и дискриминантный анализы.
Кластерный анализ применяют, когда по статистическим данным необходимо разделить элементы выборки на группы. Причем два элемента группы из одной и той же группы должны быть «близкими» по совокупности значений измеренных у них признаков, а два элемента из разных групп должны быть «далекими» в том же смысле. В отличие от дискриминантного анализа в кластер-анализе классы не заданы, а формируются в процессе обработки статистических данных. Например, кластер-анализ может быть применен для разбиения совокупности марок стали (или марок холодильников) на группы сходных между собой.
Другой вид кластер-анализа - разбиение признаков на группы близких между собой. Показателем близости признаков может служить выборочный коэффициент корреляции. Цель кластер-анализа признаков может состоять в уменьшении числа контролируемых параметров, что позволяет существенно сократить затраты на контроль. Для этого из группы тесно связанных между собой признаков (у которых коэффициент корреляции близок к 1 - своему максимальному значению) измеряют значение одного, а значения остальных рассчитывают с помощью регрессионного анализа.
Задачи группировки решают тогда, когда классы заранее не заданы и не обязаны быть «далекими» друг от друга. Примером является группировка студентов по учебным группам. В технике решением задачи группировки часто является параметрический ряд - возможные типоразмеры группируются согласно элементам параметрического ряда. В литературе, нормативно-технических и инструктивно-методических документах по прикладной статистике также иногда используется группировка результатов наблюдений (например, при построении гистограмм).
Задачи классификации решают не только в многомерном статистическом анализе, но и тогда, когда результатами наблюдений являются числа, функции или объекты нечисловой природы. Так, многие алгоритмы кластер-анализа используют только расстояния между объектами. Поэтому их можно применять и для классификации объектов нечисловой природы, лишь бы были заданы расстояния между ними. Простейшая задача классификации такова: даны две независимые выборки, требуется определить, представляют они два класса или один. В одномерной статистике эта задача сводится к проверке гипотезы однородности.
Третий раздел многомерного статистического анализа - задачи снижения размерности (сжатия информации). Цель их решения состоит в определении набора производных показателей, полученных преобразованием исходных признаков, такого, что число производных показателей значительно меньше числа исходных признаков, но они содержат возможно большую часть информации, имеющейся в исходных статистических данных. Задачи снижения размерности решают с помощью методов многомерного шкалирования, главных компонент, факторного анализа и др. Например, в простейшей модели многомерного шкалирования исходные данные - попарные расстояния между k объектами, а цель расчетов состоит в представлении объектов точками на плоскости. Это дает возможность в буквальном смысле слова увидеть, как объекты соотносятся между собой. Для достижения этой цели необходимо каждому объекту поставить в соответствие точку на плоскости так, чтобы попарные расстояния sij между точками, соответствующими объектам с номерами i и j, возможно точнее воспроизводили расстояния сijмежду этими объектами. Согласно основной идее метода наименьших квадратов находят точки на плоскости так, чтобы величина
достигала своего наименьшего значения. Есть и многие другие постановки задач снижения размерности и визуализации данных.
вероятность математический статистика качество
Социальные и экономические объекты, как правило, характеризуются достаточно большим числом параметров, образующих многомерные векторы, и особое значение в экономических и социальных исследованиях приобретают задачи изучения взаимосвязей между компонентами этих векторов, причем эти взаимосвязи необходимо выявлять на основании ограниченного числа многомерных наблюдений.
Многомерным статистическим анализом называется раздел математической статистики, изучающий методы сбора и обработки многомерных статистических данных, их систематизации и обработки с целью выявления характера и структуры взаимосвязей между компонентами исследуемого многомерного признака, получения практических выводов.
Отметим, что способы сбора данных могут различаться. Так, если исследуется мировая экономика, то естественно взять в качестве объектов, на которых наблюдаются значения вектора X, страны, если же изучается национальная экономическая система, то естественно наблюдать значения вектора X на одной и той же (интересующей исследователя) стране в различные моменты времени.
Такие статистические методы, как множественный корреляционный и регрессионный анализ, традиционно изучаются в курсах теории вероятностей и математической статистики , рассмотрению прикладных аспектов регрессионного анализа посвящена дисциплина «Эконометрика» .
Другим методам исследования многомерных генеральных совокупностей на основании статистических данных посвящено данное пособие.
Методы снижения размерности многомерного пространства позволяют без существенной потери информации перейти от первоначальной системы большого числа наблюдаемых взаимосвязанных факторов к системе существенно меньшего числа скрытых (ненаблюдаемых) факторов, определяющих вариацию первоначальных признаков. В первой главе описываются методы компонентного и факторного анализа, с использованием которых можно выявлять объективно существующие, но непосредственно не наблюдаемые закономерности при помощи главных компонент или факторов.
Методы многомерной классификации предназначены для разделения совокупностей объектов (характеризующиеся большим числом признаков) на классы, в каждый из которых должны входить объекты, в определенном смысле однородные или близкие. Такую классификацию на основании статистических данных о значениях признаков на объектах можно провести методами кластерного и дискриминантного анализа, рассматриваемыми во второй главе (Многомерный статистический анализ с использованием “STATISTICA”).
Развитие вычислительной техники и программного обеспечения способствует широкому внедрению методов многомерного статистического анализа в практику. Пакеты прикладных программ с удобным пользовательским интерфейсом, такие как SPSS, Statistica, SAS и др., снимают трудности в применении указанных методов, заключающиеся в сложности математического аппарата, опирающегося на линейную алгебру, теорию вероятностей и математическую статистику, и громоздкости вычислений.
Однако применение программ без понимания математической сущности используемых алгоритмов способствует развитию у исследователя иллюзии простоты применения многомерных статистических методов, что может привести к неверным или необоснованным результатам. Значимые практические результаты могут быть получены только на основе профессиональных знаний в предметной области, подкрепленных владением математическими методами и пакетами прикладных программ, в которых эти методы реализованы.
Поэтому для каждого из рассматриваемых в данной книге методов приводятся основные теоретические сведения, в том числе алгоритмы; обсуждается реализация этих методов и алгоритмов в пакетах прикладных программ. Рассматриваемые методы иллюстрируются примерами их практического применения в экономике с использованием пакета SPSS.
Пособие написано на основе опыта чтения курса «Многомерные статистические методы» студентам Государственного университета управления. Для более подробного изучения методов прикладного многомерного статистического анализа рекомендуются книги .
Предполагается, что читатель хорошо знаком с курсами линейной алгебры (например, в объеме учебника и приложения к учебнику ), теории вероятностей и математической статистики (например, в объеме учебника ).