विश्लेषण बहुआयामी सांख्यिकीय। बहुआयामी सांख्यिकीय विश्लेषण का परिचय - एक रैखिक प्रजनन समारोह का कालिनिना अनुमान
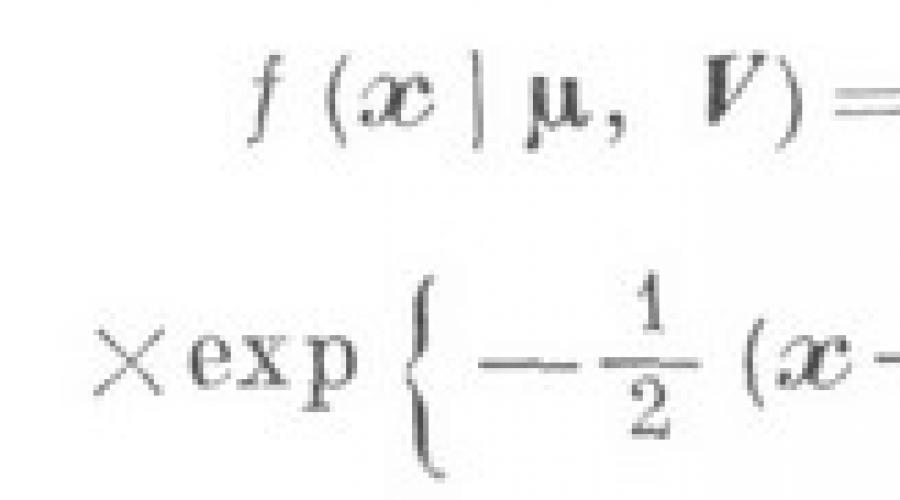
ऐसी स्थितियां हैं जिनमें एक या दो यादृच्छिक चर, सुविधाओं द्वारा यादृच्छिक परिवर्तनशीलता का प्रतिनिधित्व किया गया था।
उदाहरण के लिए, लोगों के सांख्यिकीय कुल के अध्ययन में, हम विकास और वजन में रुचि रखते हैं। इस स्थिति में, इससे कोई फर्क नहीं पड़ता कि सांख्यिकीय कुल में कितने लोग, हम हमेशा एक बिखरने वाले आरेख का निर्माण कर सकते हैं और पूरी तस्वीर को सामान्य रूप से देख सकते हैं। हालांकि, अगर संकेत तीन हैं, उदाहरण के लिए, एक संकेत जोड़ा जाता है - एक व्यक्ति की उम्र, तो बिखरने वाला आरेख त्रि-आयामी अंतरिक्ष में बनाया जाना चाहिए। वर्तमान में तीन-आयामी अंतरिक्ष में अंक की एक कुलता है पहले से ही मुश्किल है।
व्यावहारिक रूप से, प्रत्येक अवलोकन को एक या दो-तीन संख्याओं द्वारा प्रस्तुत नहीं किया जाता है, लेकिन संख्याओं के कुछ उल्लेखनीय सेट जो दर्जनों संकेतों का वर्णन करते हैं। इस स्थिति में, बहुआयामी रिक्त स्थान स्कैटरिंग आरेख बनाने की आवश्यकता होगी।
बहुआयामी अवलोकनों के साथ प्रयोगों के अध्ययन पर सांख्यिकी अनुभाग को बहुआयामी सांख्यिकीय विश्लेषण कहा जाता है।
सामान्य रूप से एक प्रयोग में कई संकेतों (ऑब्जेक्ट गुण) का मापन, किसी भी व्यक्ति के आयाम की तुलना में अधिक स्वाभाविक रूप से। इसलिए, संभावित रूप से बहुआयामी सांख्यिकीय विश्लेषण के उपयोग के लिए एक विस्तृत क्षेत्र है।
निम्नलिखित खंडों में बहुआयामी सांख्यिकीय विश्लेषण शामिल है:
कारक विश्लेषण;
विभेदक विश्लेषण;
समूह विश्लेषण;
बहुआयामी स्केलिंग;
गुणवत्ता नियंत्रण विधियों।
कारक विश्लेषण
जटिल वस्तुओं और प्रणालियों के अध्ययन में (उदाहरण के लिए, मूल्य (कारक) के मनोविज्ञान, जीवविज्ञान, समाजशास्त्र, आदि) में, इन वस्तुओं के परिभाषित गुणों, सीधे मापने के लिए अक्सर असंभव होता है, और कभी-कभी भी उनकी संख्या और सार्थक अर्थ। लेकिन ब्याज के कारकों के आधार पर अन्य मूल्य माप, एक या दूसरे के लिए उपलब्ध हो सकते हैं। साथ ही, जब कई मापा सुविधाओं में ब्याज के अज्ञात कारक का असर प्रकट होता है, तो इन सुविधाओं को स्वयं के बीच घनिष्ठ संबंध का पता लगाया जा सकता है और कारकों की कुल संख्या परिवर्तनीय-मापा चर की संख्या से बहुत कम हो सकती है।
मापा चर को प्रभावित करने वाले कारकों का पता लगाने के लिए, कारक विश्लेषण विधियों का उपयोग किया जाता है।
कारक विश्लेषण के आवेदन का एक उदाहरण मनोवैज्ञानिक परीक्षणों के आधार पर व्यक्तित्व गुणों का अध्ययन हो सकता है। व्यक्तित्व के गुण प्रत्यक्ष माप के लिए उपयुक्त नहीं हैं, उन्हें केवल मानव व्यवहार या कुछ मुद्दों के उत्तरों की प्रकृति पर न्याय किया जा सकता है। प्रयोगों के परिणामों को समझाने के लिए, वे कारक विश्लेषण के अधीन हैं, जो आपको उन व्यक्तिगत गुणों की पहचान करने की अनुमति देता है जो व्यक्तियों के विषयों के व्यवहार को प्रभावित करते हैं।
कारक विश्लेषण के विभिन्न मॉडलों के दिल में निम्नलिखित परिकल्पना है: अवलोकन या मापा पैरामीटर ऑब्जेक्ट की अप्रत्यक्ष विशेषताओं का अध्ययन किया जा रहा है या घटना, वास्तविकता में आंतरिक (छुपा, अव्यक्तसीधे नहीं देखा गया) पैरामीटर और गुण, जिसकी संख्या छोटी है और जो मनाए गए पैरामीटर के मूल्यों को परिभाषित करती है। इन आंतरिक मानकों को कारक कहा जाता है।
कारक विश्लेषण का कार्ययह कारकों के रैखिक संयोजनों के रूप में मनाए गए पैरामीटर का प्रतिनिधित्व है, शायद, कुछ अतिरिक्त, अप्रासंगिक परेशानियों।
एक नियम के रूप में, कारक विश्लेषण का पहला चरण, नए संकेतों की पसंद है जो पूर्व के रैखिक संयोजन हैं और "अवशोषित" किए गए डेटा की समग्र विविधता में से अधिकांश को "अवशोषित" करते हैं, और इसलिए प्रारंभिक अवलोकनों में संपन्न अधिकांश जानकारी संचारित करता है । यह आमतौर पर उपयोग किया जाता है मुख्य घटकों की विधि,हालांकि अन्य तकनीकों का उपयोग कभी-कभी (अधिकतम सत्य विधि) का उपयोग किया जाता है।
मुख्य घटक की विधि अवलोकनों की जगह में एक नई ऑर्थोगोनल समन्वय प्रणाली के चयन में कम हो जाती है। पहले मुख्य घटक के रूप में, दिशा निर्वाचित होती है, जिसके साथ अवलोकन सरणी में सबसे बड़ा तितरला होता है, प्रत्येक बाद के मुख्य घटक की पसंद होती है ताकि अवलोकन का टुकड़ा अधिकतम हो और यह मुख्य घटक पहले चयनित अन्य मुख्य घटकों के लिए ऑर्थोगोनल है । हालांकि, मुख्य घटक विधि द्वारा प्राप्त कारक आमतौर पर पर्याप्त रूप से दृश्य व्याख्या नहीं होते हैं। इसलिए, कारक विश्लेषण का अगला कदम परिवर्तन, व्याख्या को सुविधाजनक बनाने के लिए कारकों का घूर्णन है।
विभेदक विश्लेषण
वहां कई समूहों में टूटा हुआ वस्तुओं का संयोजन होने दें, और प्रत्येक ऑब्जेक्ट के लिए यह निर्धारित किया जा सकता है कि यह किस समूह को संदर्भित करता है। प्रत्येक वस्तु के लिए कई मात्रात्मक विशेषताओं के माप हैं। इन विशेषताओं के आधार पर एक रास्ता खोजना आवश्यक है, आप उस समूह को ढूंढ सकते हैं जिस पर वस्तु संबंधित है। यह उन समूहों को निर्दिष्ट करने की अनुमति देगा जिनके लिए नई वस्तुएं एक ही समेकित हैं। लागू कार्य को हल करने के लिए भेदभावपूर्ण विश्लेषण के तरीके।
विभेदक विश्लेषण- आंकड़ों के इस खंड, जिनकी सामग्री कुछ विशेषताओं के लिए अवलोकन वस्तुओं के भेद (भेदभाव) की समस्याओं को हल करने के तरीकों को विकसित करना है।
कुछ उदाहरणों पर विचार करें।
एक स्थिति या किसी अन्य पर रिसेप्शन की बात आती है जब परीक्षण व्यक्तियों के परिणामों को संसाधित करते समय भेदभाव विश्लेषण सुविधाजनक होता है। इस मामले में, सभी उम्मीदवारों को दो समूहों में विभाजित करने की आवश्यकता होती है: "उपयुक्त" और "उपयुक्त नहीं।"
बैंकिंग प्रशासन द्वारा ऋण जारी करते समय ग्राहक मामलों की वित्तीय स्थिति का आकलन करने के लिए भेदभाव विश्लेषण का उपयोग संभव है। कई संकेतों के लिए बैंक उन्हें विश्वसनीय और अविश्वसनीय रूप से वर्गीकृत करता है।
भेदभाव विश्लेषण उत्पादन और आर्थिक गतिविधियों के किसी भी संकेतक के मूल्यों पर कई सजातीय समूहों में उद्यमों के एक सेट को विभाजित करने की विधि के रूप में आकर्षित किया जा सकता है।
भेदभावपूर्ण विश्लेषण विधियां मापा गई विशेषताओं के कार्यों को बनाने के लिए संभव बनाती हैं, जिनमें से मूल्यों को समूहों में वस्तुओं को अलग करने और समझाने के लिए संभव है। यह वांछनीय है कि ये कार्य (भेदभावपूर्ण संकेत)थोड़ा सा था। इस मामले में, विश्लेषण परिणामों की व्याख्या करना आसान है।
इसकी सादगी के कारण, एक रैखिक भेदभाव विश्लेषण एक विशेष भूमिका से खेला जाता है, जिसमें वर्गीकरण सुविधाओं को प्राथमिक संकेतों से रैखिक कार्यों के रूप में चुना जाता है।
समूह विश्लेषण
क्लस्टर विश्लेषण के तरीके आपको क्लस्टर नामक "समान" वस्तुओं के समूहों में वस्तुओं के अध्ययन सेट को तोड़ने की अनुमति देते हैं।
शब्द समूहअंग्रेजी मूल - क्लस्टर के रूप में अनुवाद करता है ब्रश, बंडल, समूह, झुंड, क्लस्टर।
क्लस्टर विश्लेषण निम्नलिखित कार्यों को हल करता है:
उन सभी उन संकेतों के साथ वस्तुओं का वर्गीकरण आयोजित करता है जो वस्तु को दर्शाते हैं। वर्गीकरण की संभावना हमें उसमें शामिल कुल और वस्तुओं की अधिक गहराई से समझ को बढ़ावा देती है;
यह मौजूदा कुलता में प्राथमिकता परिभाषित संरचना या वर्गीकरण की उपस्थिति की जांच करने का कार्य रखता है। इस तरह की जांच वैज्ञानिक अनुसंधान की मानक काल्पनिक और कटौतीत्मक योजना का लाभ उठाना संभव बनाता है।
अधिकांश क्लस्टरिंग विधियां (पदानुक्रमित समूह) हैं सहज(कॉम्प्रिजिनल) - वे प्राथमिक क्लस्टर के निर्माण से शुरू होते हैं, जिनमें से प्रत्येक में एक स्रोत अवलोकन (एक बिंदु) के समान होता है, और प्रत्येक बाद के चरण में, दो निकटतम क्लस्टर एक में संयुक्त होते हैं।
इस प्रक्रिया को रोकने का क्षण शोधकर्ता द्वारा परिभाषित किया जा सकता है (उदाहरण के लिए, वांछित संख्याओं की वांछित संख्या या अधिकतम दूरी को इंगित करके, जिसमें मर्ज किया जाता है)।
क्लस्टर संयोजन प्रक्रिया की ग्राफिक छवि द्वारा प्राप्त की जा सकती है डेंड्रोग्राम- पेड़ संयोजन क्लस्टर।
निम्नलिखित उदाहरण पर विचार करें। हम पांच उद्यमों को वर्गीकृत करेंगे, जिनमें से प्रत्येक को तीन चर द्वारा विशेषता है:
एक्स 1- मुख्य उत्पादन सुविधाओं, अरब rubles का औसत वार्षिक मूल्य;
एक्स 2- 1 रगड़ के लिए सामग्री लागत। उत्पादित उत्पाद, पुलिस।;
x 3- निर्मित उत्पादों की मात्रा, अरब रूबल।
राष्ट्रीय अर्थव्यवस्था के प्रबंधन में पीईवीएम की शुरूआत में उद्यमों का विश्लेषण करने के लिए पारंपरिक तरीकों से संक्रमण शामिल है जो अधिक उन्नत अर्थव्यवस्था प्रबंधन मॉडल में है जो इसकी गहराई प्रक्रियाओं को प्रकट करने की अनुमति देता है।
गणितीय आंकड़ों के तरीकों के आर्थिक अध्ययन में व्यापक उपयोग आर्थिक विश्लेषण को गहरा बनाना, उत्पादन संकेतकों की योजना बनाने और भविष्यवाणी करने और इसकी प्रभावशीलता का विश्लेषण करने में जानकारी की गुणवत्ता में सुधार करना संभव बनाता है।
आर्थिक संकेतकों के संबंधों की जटिलता और विविधता संकेतों की बहुसंख्यकता निर्धारित करती है और इसके संबंध में अधिकांश जटिल गणितीय तंत्र के उपयोग की आवश्यकता होती है - बहुआयामी सांख्यिकीय विश्लेषण के तरीके।
"बहुआयामी सांख्यिकीय विश्लेषण" की अवधारणा से अंतःसंबंधित संकेतों के संयोजन का पता लगाने के लिए डिज़ाइन की गई कई विधियों का तात्पर्य है। हम विचार के तहत संयोजन के विघटन (विभाजन) के बारे में बात कर रहे हैं, जिसका प्रतिनिधित्व अपेक्षाकृत कम मात्रा में बहुआयामी संकेतों द्वारा किया जाता है।
साथ ही, बड़ी संख्या में संकेतों से संक्रमण को उनके आयाम को कम करने और सूचनात्मक कंटेनर में वृद्धि के लक्ष्य से प्रेतवाधित किया जाता है। इस तरह का लक्ष्य कुछ संकेतों के लिए एकत्रीकरण (एसोसिएशन, सारांश) की संभावना स्थापित करने, पारस्परिक संकेतों द्वारा उत्पन्न जानकारी की पहचान करके, दोहराया गया है। उत्तरार्द्ध में एक मॉडल में वास्तविक मॉडल का परिवर्तन शामिल होता है जिसमें कारक संकेतों की एक छोटी संख्या होती है।
बहुआयामी सांख्यिकीय विश्लेषण की विधि आपको निष्पक्ष रूप से मौजूदा लोगों की पहचान करने की अनुमति देती है, लेकिन कुछ सामाजिक-आर्थिक घटनाओं में प्रकट होने वाले पैटर्न को स्पष्ट रूप से व्यक्त नहीं किया जाता है। इसे अर्थशास्त्र के क्षेत्र में कई व्यावहारिक कार्यों को हल करने में इसका सामना करना पड़ता है। विशेष रूप से, कब्जे में कहा गया है कि एक ही समय में एक ही समय में जमा करने के लिए आवश्यक है (ठीक है) जैसे ऑब्जेक्ट पर कई मात्रात्मक विशेषताओं (सुविधाओं) के मूल्यों का अध्ययन किया जा रहा है जब प्रत्येक विशेषता अनियंत्रित भिन्नता (वस्तुओं के संदर्भ में) की प्रवण होती है , अवलोकन वस्तुओं की एकरूपता के बावजूद।
उदाहरण के लिए, कई प्रदर्शन प्रदर्शन संकेतकों के लिए उद्यम के सजातीय (प्राकृतिक आर्थिक स्थितियों और विशेषज्ञता के प्रकार) की खोज करते हुए, हम आश्वस्त हैं कि एक वस्तु से दूसरे ऑब्जेक्ट में संक्रमण में, लगभग प्रत्येक चयनित विशेषताओं (समान) के पास है एक असमान अर्थ, यानी, यह अनियंत्रित (यादृच्छिक) स्कैटर बोलने के लिए मिलता है। एक नियम के रूप में, इस तरह के "यादृच्छिक" विशेषता, एक नियम के रूप में, कुछ (प्राकृतिक) रुझानों के अधीन है, दोनों पर्याप्त विशिष्ट आकार के संदर्भ में, जिसके आसपास भिन्नता और भिन्नता की डिग्री और परस्पर निर्भरता के मामले में ही किया जाता है बाहर।
उपरोक्त मात्रात्मक सुविधाओं के एक सेट के रूप में एक बहुआयामी यादृच्छिक चर की परिभाषा की ओर जाता है, जिनमें से प्रत्येक का मूल्य इस प्रक्रिया की पुनरावृत्ति, सांख्यिकीय अवलोकन, अनुभव, प्रयोग इत्यादि के दौरान अनियंत्रित स्कैटर के अधीन है।
यह पहले कहा गया था कि एक बहु-आयामी विश्लेषण कई तरीकों को जोड़ता है; हम उन्हें कहते हैं: कारक विश्लेषण, मुख्य घटक विधि, क्लस्टर विश्लेषण, छवि मान्यता, भेदभाव विश्लेषण और आदि। इन विधियों में से पहले तीन निम्नलिखित अनुच्छेदों में विचार किया जाता है।
अन्य गणितज्ञ की तरह - सांख्यिकीय विधियों, बहु-आयामी विश्लेषण प्रारंभिक जानकारी की उच्च गुणवत्ता और इन अवलोकनों के द्रव्यमान के अधीन अपने आवेदन में प्रभावी हो सकता है, पीईवीएम का उपयोग करके संसाधित किया जाता है।
कारक विश्लेषण की विधि की मूल अवधारणाएं, उनके द्वारा हल किए गए कार्यों का सार
जब विश्लेषण (समान रूप से और जांच की गई), सामाजिक और आर्थिक घटना अक्सर उन मामलों में पाए जाते हैं जहां विविधता (bagatoparametrimetrityity) अवलोकन वस्तुओं के बीच, पैरामीटर के अनुपात को बाहर करने के लिए आवश्यक है, या बिना किसी कारण के कुछ कार्यों की एक छोटी संख्या के साथ उन्हें प्रतिस्थापित करना आवश्यक है अखंडता (पूर्ण) जानकारी की अखंडता। इस तरह के एक कार्य का समाधान एक निश्चित मॉडल के भीतर समझ में आता है और इसकी संरचना के कारण होता है। ऐसे मॉडल का एक उदाहरण जो कई वास्तविक परिस्थितियों के लिए सबसे उपयुक्त है, एक कारक विश्लेषण मॉडल है, जिनमें से बड़ी संख्या में कम संख्या के "संघनन" द्वारा संकेतों (उनके बारे में जानकारी) पर ध्यान केंद्रित करना संभव हो जाता है। इस मामले में, जानकारी के प्राप्त "संघनन" को सबसे महत्वपूर्ण और निर्धारित मात्रात्मक विशेषताओं द्वारा दर्शाया जाना चाहिए।
"कारक विश्लेषण" की अवधारणा को कारण संबंधों के विश्लेषण की व्यापक अवधारणा के साथ मिश्रित करने की आवश्यकता नहीं है, जब विभिन्न कारकों (उनके संयोजनों, संयोजनों) के प्रभाव को उत्पादक आधार पर अध्ययन किया जा रहा है।
कारक विश्लेषण की विधि का सार अध्ययन और प्रतिस्थापन की कई विशेषताओं के विवरण को अपनी छोटी संख्या और अधिक शक्तिशाली चर के विवरण को बहिष्कृत करना है, जिन्हें कारकों कहा जाता है और घटनाओं के सबसे महत्वपूर्ण गुणों को प्रतिबिंबित किया जाता है। ऐसे चर स्रोत संकेतों की कुछ विशेषताएं हैं।
विश्लेषण, के अनुसार, पर्च 9 के अनुसार, आपको घटना के अंतर्निहित पैटर्न की पहली अनुमानित विशेषताओं की अनुमति देता है, जो कि निर्देशों के बारे में पहले, सामान्य निष्कर्ष तैयार करता है, जिसमें आगे अनुसंधान किया जाना चाहिए। इसके अलावा, यह कारक विश्लेषण की मुख्य धारणा को इंगित करता है, जो इस तथ्य को कम कर देता है कि इसकी विषमता और परिवर्तनशीलता के बावजूद घटना को कार्यात्मक इकाइयों, पैरामीटर या कारकों की एक छोटी संख्या द्वारा वर्णित किया जा सकता है। इन तिथियों को अलग-अलग कहा जाता है: प्रभाव, कारण, पैरामीटर, कार्यात्मक इकाइयों, क्षमताओं, मूल या स्वतंत्र संकेतक। एक या किसी अन्य शब्द का उपयोग होने के कारण होता है
ओकुन I. कारक विश्लेषण: प्रति। से। मंज़िल। एम।: सांख्यिकी, 1 9 74.- P.16।
अध्ययन की घटना के सार और ज्ञान का संदर्भ।
कारक विश्लेषण के चरण समूहों के बीच मतभेदों की विश्वसनीयता की विश्वसनीयता के समावेश, शटडाउन और मूल्यांकन के साथ समूहों के विभिन्न सेटों के विभिन्न सेटों की लगातार तुलना कर रहे हैं।
वीएम zhukovska और i.b mutnik 10, कारक विश्लेषण के कार्यों के सार की बात करते हुए, तर्क देते हैं कि बाद वाले को आश्रित और स्वतंत्र पर चर के प्राथमिक विभाजन की आवश्यकता नहीं होती है, क्योंकि सभी चर को बराबर माना जाता है।
कारक विश्लेषण का कार्य एक निश्चित अवधारणा, घटना, उसके मीटर या मूल पैरामीटर की सबसे महत्वपूर्ण और अपेक्षाकृत स्वतंत्र कार्यात्मक विशेषताओं की संख्या और प्रकृति को कम कर दिया गया है - कारक। लेखकों के मुताबिक, कारक विश्लेषण की एक महत्वपूर्ण विशिष्ट विशेषता यह है कि यह विश्लेषण के कई अन्य तरीकों का उपयोग करते समय आवश्यकतानुसार "अन्य सभी स्थितियों" के बारे में मान्यताओं के बिना बड़ी संख्या में पारस्परिक चर का पता लगाने की अनुमति देता है। जटिल विविधता और कनेक्शन की रिफाइनरियों के कारण घटना के एक मूल्यवान अध्ययन उपकरण के रूप में यह कारक विश्लेषण का यह बड़ा फायदा है।
विश्लेषण मुख्य रूप से प्राकृतिक विभिन्न भिन्नता की निगरानी करने के लिए निर्भर करता है।
1. कारक विश्लेषण का उपयोग करते समय, उनके बीच के लिंक के दृष्टिकोण से अध्ययन किए जाने वाले चर का सेट मनमाने ढंग से नहीं चुना जाता है: यह विधि आपको इस क्षेत्र में महत्वपूर्ण प्रभाव डालने वाले मुख्य कारकों की पहचान करने की अनुमति देती है।
2. विश्लेषण को प्रारंभिक परिकल्पनाओं की आवश्यकता नहीं होती है, इसके विपरीत, यह स्वयं एक परिकल्पना के रूप में कार्य कर सकता है, साथ ही अन्य तरीकों से प्राप्त डेटा के आधार पर परिकल्पना के मानदंड के रूप में कार्य कर सकता है।
3. विश्लेषण को प्राथमिकता के लिए प्राथमिकता की आवश्यकता नहीं होती है कि कौन से चर स्वतंत्र हैं, और निर्भर करते हैं, यह कारण संचार को हाइपरट्रॉफी नहीं करता है और आगे के शोध की प्रक्रिया में अपनी सीमा के मुद्दे को हल करता है।
फैक्टर विश्लेषण के तरीकों का उपयोग करके हल किए गए विशिष्ट कार्यों की सूची इस तरह की होगी (वी.एम. Zhukovskoy द्वारा)। चलो सामाजिक-आर्थिक अनुसंधान के क्षेत्र में मुख्य लोगों को बुलाते हैं:
Zhukovskaya v.m., mulanik i.b. सामाजिक-आर्थिक अनुसंधान में कारक विश्लेषण। -स्टेशन, 1 9 76. पी 4।
1. अवलोकन वस्तुओं (न्यूनतम विवरण) के बीच मतभेदों के मुख्य पहलुओं का निर्धारण।
2. वस्तुओं के बीच मतभेदों की प्रकृति के बारे में परिकल्पना का शब्द।
3. संकेतों के बीच संबंधों की संरचना का पता लगाना।
4. संबंधों के संबंध और विनिमयशीलता के बारे में परिकल्पना की जांच करना।
5. विशेषता सेट संरचनाओं की तुलना।
6. ठेठ विशेषताओं के लिए अवलोकन वस्तुओं की विघटन।
उपरोक्त में कारक विश्लेषण की बड़ी संभावनाओं को इंगित करता है
सामाजिक घटनाओं का अध्ययन, जहां एक नियम के रूप में, व्यक्तिगत कारकों के प्रभाव को नियंत्रित करना (प्रयोगात्मक रूप से) करना असंभव है।
कई रिग्रेशन मॉडल में कारक विश्लेषण के परिणामों का उपयोग करने के लिए काफी प्रभावी है।
कारक विश्लेषण का उपयोग करके सहसंबंधित संकेतों के रूप में अध्ययन की घटना का पूर्वनिर्धारित सहसंबंध-प्रतिगमन मॉडल होने के बाद, आप एकत्रीकरण द्वारा काफी छोटी संख्या में बदलने के लिए संकेतों का एक सेट कर सकते हैं। इस मामले में, यह ध्यान दिया जाना चाहिए कि इस तरह का परिवर्तन किसी भी तरह से खराब नहीं होता है और माना गया घटना के बारे में जानकारी पूरी करता है। निर्मित समेकित संकेत असंबद्ध हैं और प्राथमिक संकेतों के एक रैखिक संयोजन का प्रतिनिधित्व करते हैं। एक औपचारिक गणितीय पक्ष के साथ, इस मामले में कार्यों को स्थापित करने के लिए कई समाधान हो सकते हैं। लेकिन यह याद रखना चाहिए कि सामाजिक-आर्थिक घटनाओं का अध्ययन करते समय, प्राप्त समेकित संकेतों में आर्थिक रूप से सूचित व्याख्या होनी चाहिए। दूसरे शब्दों में, गणितीय तंत्र के उपयोग के किसी भी मामले में, सबसे पहले अध्ययन किए गए घटनाओं के आर्थिक सार के ज्ञान को नजरअंदाज कर दिया गया है।
इस प्रकार, उपर्युक्त उपर्युक्त आपको सारांशित करने की अनुमति देता है कि कारक विश्लेषण एक विशिष्ट अध्ययन विधि है, जिसे गणितीय आंकड़ों के तरीकों के शस्त्रागार के आधार पर किया जाता है।
कारक विश्लेषण को पहले मनोविज्ञान के क्षेत्र में अपना व्यावहारिक अनुप्रयोग मिला। बड़ी संख्या में कारकों को बड़ी संख्या में मनोवैज्ञानिक परीक्षणों को कम करने की क्षमता ने मानव बुद्धि की क्षमताओं को समझाने के लिए संभव बना दिया।
सामाजिक-आर्थिक घटनाओं के अध्ययन में, जहां अलग-अलग चर के प्रभाव को अलग करने में कठिनाइयां हैं, एक कारक विश्लेषण का सफलतापूर्वक उपयोग किया जा सकता है। इसकी तकनीकों का उपयोग कुछ गणनाओं को "प्रोफ़ाइल" महत्वहीन संकेतों के लिए अनुमति देता है और इसकी गहराई की दिशा में अनुसंधान जारी रखता है।
इस विधि की प्रभावशीलता इस तरह के मुद्दों (समस्याओं) के अध्ययन में स्पष्ट है: अर्थव्यवस्था में - विशेषज्ञता और उत्पादन की एकाग्रता, अर्थव्यवस्था के प्रबंधन की तीव्रता, श्रमिकों के परिवारों का बजट, विभिन्न सामान्यीकरण संकेतकों का निर्माण। आदि
बहुआयामी सांख्यिकीय विश्लेषण
अनुभाग गणित। सांख्यिकी गणित को समर्पित। इष्टतम संग्रह योजना, व्यवस्थितकरण और प्रसंस्करण multidimensional सांख्यिकीय सांख्यिकीय निर्माण के लिए तरीके। अध्ययन के तहत बहुआयामी विशेषता के घटकों के बीच हस्तक्षेप की प्रकृति और संरचना की पहचान करना है और वैज्ञानिक और व्यावहारिक प्राप्त करने के इरादे से। निष्कर्ष एक बहुआयामी संकेत के तहत, पी-आयामी संकेतक (संकेत, चर) हो सकते हैं: मात्रात्मक, यानी, स्केलर रूप से अध्ययन की जा रही वस्तु के प्रकटीकरण के एक विशिष्ट पैमाने पर मापा जाता है, एन-पंक्ति (या क्रमिक), यानी विश्लेषण को सॉर्ट करने की अनुमति देता है अध्ययन के तहत संपत्ति के प्रकटीकरण की डिग्री के अनुसार वस्तुओं; और वर्गीकरण (या नाममात्र), यानी गैर-ऑर्डरिंग वर्दी (विश्लेषण की गई संपत्ति के अनुसार) कक्षाओं के लिए वस्तुओं के अध्ययन सेट को तोड़ने की अनुमति। इन संकेतकों के माप परिणाम
अध्ययन के तहत प्रत्येक अनुभाग, बहुआयामी अवलोकन का गठन किया गया है, या एम एस के लिए बहुआयामी डेटा का स्रोत सरणी है। लेकिन अ। एम एस का महत्वपूर्ण हिस्सा। लेकिन अ। परिस्थितियों की सेवा करता है, जिसमें अध्ययन किए गए बहुआयामी सुविधा को बहुआयामी के रूप में व्याख्या किया जाता है और तदनुसार, बहुआयामी अवलोकनों (1) का अनुक्रम सामान्य आबादी से है। इस मामले में, स्रोत सांख्यिकीय सांख्यिकीय संसाधित करने के तरीकों की पसंद। संभाव्यता वितरण के बहुआयामी (संयुक्त) कानून की प्रकृति के बारे में कुछ मान्यताओं के आधार पर उनकी संपत्तियों का डेटा और विश्लेषण किया जाता है
बहुआयामी वितरण के बहुआयामी सांख्यिकीय विश्लेषण और उनकी मुख्य विशेषताओं में केवल स्थितियों को शामिल किया गया है जिनमें संसाधित अवलोकन (1) में एक संभाव्य प्रकृति होती है, जिसे इसी सामान्य आबादी से नमूना के रूप में व्याख्या किया जाता है। इस उपधारा के मुख्य कार्यों में सांख्यिकीय शामिल हैं। अध्ययन किए गए बहुआयामी वितरण का मूल्यांकन, उनकी मुख्य संख्यात्मक विशेषताओं और पैरामीटर; प्रयुक्त सांख्यिकीय गुणों का अध्ययन। अनुमान; कई आंकड़ों के लिए संभाव्यता वितरण की जांच, सांख्यिकीय एक टू-रायख का उपयोग करके बनाया जा रहा है। विश्लेषण किए गए बहुआयामी डेटा की संभाव्य प्रकृति के बारे में विभिन्न परिकल्पनाओं की जांच के लिए मानदंड। मुख्य परिणाम एक निजी मामले का उल्लेख करते हैं जब अध्ययन की गई सुविधा बहुआयामी सामान्य वितरण कानून के अधीन होती है, तो के-पोगो के घनत्व समारोह को संबंध द्वारा दिया जाता है

जहां - वेक्टर गणित। एक यादृच्छिक चर के अपेक्षाएं घटक, यानी ![]() - एक यादृच्छिक वेक्टर, टी के कोवेरियन मैट्रिक्स। ई। वेक्टर के घटक के घटक (एक nondegenerate मामले माना जाता है, जब; अन्यथा, यानी, रैंक के दौरान, सभी परिणाम निष्पक्ष रहते हैं, लेकिन एक छोटे से उप-स्थान के संबंध में आयाम, यह अंतर्निहित यादृच्छिक वेक्टर केंद्रित होने के लिए बाहर निकलता है)।
- एक यादृच्छिक वेक्टर, टी के कोवेरियन मैट्रिक्स। ई। वेक्टर के घटक के घटक (एक nondegenerate मामले माना जाता है, जब; अन्यथा, यानी, रैंक के दौरान, सभी परिणाम निष्पक्ष रहते हैं, लेकिन एक छोटे से उप-स्थान के संबंध में आयाम, यह अंतर्निहित यादृच्छिक वेक्टर केंद्रित होने के लिए बाहर निकलता है)।
तो, यदि (1) स्वतंत्र अवलोकनों का एक अनुक्रम है जो पैरामीटर के लिए अधिकतम संभावना अनुमानों से एक यादृच्छिक नमूना बनाते हैं और (2) में भाग लेने के अनुसार आंकड़े हैं (देखें)
और यादृच्छिक वेक्टर पी-आयामी सामान्य कानून के अधीन है। ![]() और इस पर निर्भर नहीं है, और मैट्रिक्स के तत्वों के संयुक्त वितरण को टीएन द्वारा वर्णित किया गया है। विशा आरआर का वितरण। ए (देखें), करने के लिए
और इस पर निर्भर नहीं है, और मैट्रिक्स के तत्वों के संयुक्त वितरण को टीएन द्वारा वर्णित किया गया है। विशा आरआर का वितरण। ए (देखें), करने के लिए

एक ही योजना के ढांचे के भीतर, एक बहुआयामी यादृच्छिक चर की इस तरह की चुनिंदा विशेषताओं के वितरण और क्षण, जोड़ी, निजी और एकाधिक सहसंबंध, सामान्यीकृत (आईई) के गुणांक (आईई) के गुणांक (देखें) की जांच की गई थी । विशेष रूप से (देखें), यदि एक चुनिंदा कोवेरियस मैट्रिक्स के रूप में परिभाषित किया गया है, तो अनुमान, अर्थात् "विफलता पर", अर्थात्:
फिर यादृच्छिक चर ![]() जब, और यादृच्छिक चर के लिए प्रयास करें
जब, और यादृच्छिक चर के लिए प्रयास करें

स्वतंत्रता की डिग्री के साथ एफ-वितरण के अधीनस्थ, क्रमशः (पी, पी-पी) और (पी, पी 1 + पी 2 -R-1)। संबंध में (7) पी 1। और एन 2 फॉर्म के दो स्वतंत्र नमूनों की मात्रा (1) समान सामान्य समुच्चय से निकाले गए - फॉर्म (3) और (4) - (5) के अनुमान से निकाले गए, और आई-वें नमूना के अनुसार बनाया गया, और
सामान्य चुनिंदा कॉन्वेरियस, अनुमानों के अनुसार बनाया गया है और
हस्तक्षेप की प्रकृति और संरचना के बहुआयामी सांख्यिकीय विश्लेषण अध्ययन बहुआयामी विशेषता के घटक अवधारणाओं और परिणामों को इस तरह के विधियों और मॉडल एम एस की सेवा करते हैं। साथ ही साथ कई, बहुआयामी फैलाव विश्लेषण तथा कॉवरग्रीन्स विश्लेषण, कारक विश्लेषण और मुख्य घटक विधि, कैननिक का विश्लेषण। सहसंबंध। इस उपधारा की सामग्री बनाने वाले परिणाम सशर्त रूप से दो मुख्य प्रकारों में विभाजित किए जा सकते हैं।
1) सांख्यिकीय (एक निश्चित अर्थ में) का निर्माण करना। उल्लिखित मॉडल के मानकों के लिए अनुमान और उनके गुणों (सटीकता, और उनके वितरण के कानूनों के संभाव्य फॉर्मूलेशन में, विश्वसनीय: क्षेत्र, आदि) के विश्लेषण के लिए अनुमान। इसलिए, अध्ययनित बहु-आयामी विशेषता को एक वेक्टर यादृच्छिक के रूप में व्याख्या करने दें, पी-आयामी सामान्य वितरण के अधीनस्थ, और दो क्षेत्र - कॉलम और क्यू और पी-क्यूएस की आयाम से विच्छेदन किया जाता है। यह गणित वेक्टर के संबंधित विघटन को निर्धारित करता है। उम्मीदें, सैद्धांतिक और चुनिंदा कॉन्वेरियन मैट्रिसेस, अर्थात्:
फिर (देखें,) मीटर (बशर्ते कि दूसरे समर्थक ने निश्चित मूल्य स्वीकार किया) भी सामान्य होगा)। इस मामले में, अधिकतम विश्वास के अनुमान। एकाधिक प्रतिगमन के इस शास्त्रीय बहुआयामी मॉडल के प्रतिगमन गुणांक और कोवरियातियों के matrices के लिए
क्रमशः परस्पर स्वतंत्र आंकड़े होंगे
यहां मूल्यांकन का वितरण सामान्य कानून के अधीन है ![]() , और पी के अनुमान - पैरामीटर के साथ इच्छावादी कानून और (कोवेरियन मैट्रिक्स के तत्व मैट्रिक्स के तत्वों के संदर्भ में व्यक्त किए जाते हैं)।
, और पी के अनुमान - पैरामीटर के साथ इच्छावादी कानून और (कोवेरियन मैट्रिक्स के तत्व मैट्रिक्स के तत्वों के संदर्भ में व्यक्त किए जाते हैं)।
पैरामीटर अनुमानों के निर्माण और कारक के मॉडल में उनके गुणों में उनके गुणों के अध्ययन पर मुख्य परिणाम "विश्लेषण, मुख्य घटक और कैननिकल। सहसंबंध संभाव्यता सांख्यिकीय के विश्लेषण को संदर्भित करते हैं। स्वयं (विशेषता) मूल्यों और वैक्टरों की गुण विभिन्न चुनिंदा कॉन्वेरियस मैट्रिसेस।
उन योजनाओं में जो क्लासिक के ढांचे में फिट नहीं हैं। सामान्य मॉडल और यहां तक \u200b\u200bकि किसी भी संभाव्य मॉडल के ढांचे में, मुख्य परिणाम पैरामीटर के अनुमानों की गणना करने वाले एल्गोरिदम (और उनके गुणों का अध्ययन) के निर्माण का संदर्भ देते हैं, जो एक के ने-पोरो के संदर्भ में सबसे अच्छा है एक्सोजेनस रूप से निर्दिष्ट गुणवत्ता कार्यात्मक (संदर्भ) मॉडल।
2) सांख्यिकीय बिल्डिंग। अध्ययन के तहत हस्तक्षेप की संरचना के बारे में विभिन्न परिकल्पनाओं का परीक्षण करने के लिए मानदंड। एक बहुआयामी सामान्य मॉडल (फॉर्म (1) के अवलोकनों के अनुक्रम के रूप में, इसे संबंधित बहुआयामी सामान्य सामान्य समेकन से यादृच्छिक नमूने के रूप में व्याख्या किया जाता है), उदाहरण के लिए, सांख्यिकीय। निम्नलिखित परिकल्पनाओं की जांच के लिए मानदंड।
I. वेक्टर गणित की समानता के बारे में परिकल्पना। अध्ययन निर्दिष्ट विशिष्ट वेक्टर के तहत संकेतकों की अपेक्षाएं; सूत्र (6) में एक प्रतिस्थापन के साथ विशैला के आंकड़ों की मदद से चेक किया गया
द्वितीय। गणित के वैक्टर की समानता के बारे में परिकल्पना। दो आम कुलों में अपेक्षाएं (एक ही, लेकिन अज्ञात कॉन्वर्सी मैट्रिस) के साथ दो नमूनों द्वारा प्रतिनिधित्व किया गया; आंकड़ों के साथ जाँच की गई (देखें)।
तृतीय। गणित के वैक्टर की समानता के बारे में परिकल्पना। कई सामान्य सहयोगों में उम्मीदें (उसी के साथ, लेकिन अज्ञात कॉन्वेरियन मैट्रिक्स) उनके नमूने द्वारा जमा की गई; आंकड़ों द्वारा जाँच की गई
की-रॉय में, जूनियर का प्रतिनिधित्व करने वाली मात्रा के नमूने में एक आईई पी-आयामी अवलोकन होता है। सामान्य कुल योग का प्रतिनिधित्व, ए और - अनुमान (3), प्रत्येक नमूने के लिए अलग-अलग और संयुक्त नमूने के लिए अलग से बनाया गया आयतन
Iv। उनके नमूने द्वारा प्रस्तुत कई सामान्य सामान्य योगों के समानता के बारे में परिकल्पना आंकड़ों से जांच की जाती है

की-रॉय में - प्रपत्र (4) का मूल्यांकन, अवलोकन द्वारा अलग से बनाया गया जे- Yexibers, J \u003d 1, 2, ..., क।
वी। परिकल्पना स्तंभ की पारस्परिक स्वतंत्रता पर परिकल्पना क्रमशः, के-राई प्रसारित, परीक्षण संकेतकों के प्रारंभिक पी-आयामी वेक्टर आंकड़ों द्वारा जांच की जाती है

के-रॉय में और - पूरे वेक्टर के लिए और इसके स्थान के लिए फॉर्म (4) के चयनात्मक कोवेरियन मैट्रिस एक्स। (i), क्रमशः।
बहुआयामी अवलोकनों के जांच किए गए सेट की ज्यामितीय संरचना का बहुआयामी सांख्यिकीय विश्लेषण इस तरह के मॉडल और योजनाओं के अवधारणाओं और परिणामों को जोड़ता है विभेदक विश्लेषण संभाव्य वितरण, क्लस्टर विश्लेषण और वर्गीकरण, बहुआयामी स्केलिंग के मिश्रण। विश्लेषण किए गए तत्वों के बीच दूरी (निकटता उपाय, समानता उपाय) की अवधारणा इन सभी योजनाओं में नोडल है। साथ ही, वास्तविक वस्तुओं के रूप में, संकेतकों के मूल्यों को विश्लेषण किया जाता है, जिनमें से प्रत्येक, फिर जियोमेट्रिच पर। आई-वें सर्वेक्षित ऑब्जेक्ट की छवि संबंधित पी-आयामी अंतरिक्ष में एक बिंदु होगी, और संकेतक स्वयं जियोमेट्रिच हैं। एल-वें संकेतक संबंधित एन-आयामी अंतरिक्ष में एक बिंदु होगा।
भेदभाव विश्लेषण के तरीके और परिणाम (देखें,) अगले कार्य पर निर्देशित हैं। यह सामान्य कुल संख्या की एक निश्चित संख्या के अस्तित्व के बारे में जानता है और शोधकर्ता के पास प्रत्येक कुटिलता ("प्रशिक्षण नमूना") से एक नमूना है। एक निश्चित अर्थ में सर्वोत्तम-आधारित वर्गीकृत नमूने बनाने के लिए आवश्यक है, जो आपको अपनी सामान्य आबादी को ऐसी स्थिति में एक नए नए तत्व (अवलोकन) को विशेषता देने की अनुमति देता है जहां शोधकर्ता को पहले से ही इस तत्व को समेकित करने के लिए नहीं जाना जाता है संबंधित है। आम तौर पर, वर्गीकरण नियम के तहत, क्रियाओं का अनुक्रम समझा जाता है: के-रॉय के मूल्यों के अनुसार जांचकर्ताओं के तहत परीक्षण संकेतकों से स्केलर फ़ंक्शन की गणना करने के लिए, एक निर्णय को एक तत्व को असाइन करने के लिए किया जाता है कक्षाएं (एक भेदभावपूर्ण कार्य का निर्माण); कक्षाओं के तत्वों के सही एट्रिब्यूशन के संदर्भ में संकेतकों को अपनी अनौपचारिकता की डिग्री से खुद को आदेश देने में; गलत वर्गीकरण की संबंधित संभावनाओं की गणना करके।
संभाव्यता वितरण के मिश्रणों का विश्लेषण करने का कार्य (देखें) कुल आबादी के "ज्यामितीय संरचना" के अध्ययन में अक्सर (लेकिन हमेशा नहीं) उत्पन्न होता है। इस मामले में, आर-वें सजातीय वर्ग की अवधारणा को कुछ सामान्य आबादी की मदद से औपचारिक रूप से माना जाता है (एक नियम के रूप में, एक अलग-अलग) वितरण कानून ताकि सामान्य सामान्य सेट का वितरण, नमूना (1) ) झुंड से निकाला जाता है, प्रजातियों के वितरण के मिश्रण द्वारा वर्णित किया गया है जहां पीआर - सामान्य जनसंख्या में आर वर्ग के प्राथमिकता (विशिष्ट तत्व)। यह कार्य "अच्छा" सांख्यिकीय है। अज्ञात पैरामीटर के अनुमान (नमूना द्वारा) और कभी-कभी और सेवा मेरे। यह विशेष रूप से, आपको एक भेदभाव विश्लेषण योजना में वर्गीकृत तत्वों के कार्य को कम करने की अनुमति देता है, हालांकि इस मामले में कोई प्रशिक्षण नमूने नहीं थे।
क्लस्टर विश्लेषण के तरीके और परिणाम (वर्गीकरण, वर्गीकरण, छवियों की मान्यता "शिक्षक के बिना", देखें,) का उद्देश्य निम्नलिखित कार्य को हल करना है। जियोमेट्रिच तत्वों का विश्लेषण सेट या तो संबंधित बिंदुओं के निर्देशांक (यानी, मैट्रिक्स ..., पी) द्वारा दिया जाता है , या जियोमेट्रिच का एक सेट। उनके पारस्परिक स्थान की विशेषताएं, उदाहरण के लिए, जोड़ीदार दूरी के मैट्रिक्स। अपेक्षाकृत छोटे (ज्ञात या नहीं) कक्षाओं पर तत्वों के अध्ययन सेट को तोड़ने की आवश्यकता होती है ताकि एक ही वर्ग के तत्व एक-दूसरे से थोड़ी दूरी पर हों, जबकि विभिन्न वर्ग एक दूसरे से काफी पारस्परिक रूप से जुड़े होंगे और करेंगे एक दूसरे से हटाए गए समान भागों में विभाजित नहीं किया जाना चाहिए।
बहुआयामी स्केलिंग की समस्या (देखें) स्थिति को संदर्भित करती है जब तत्वों की कुलता जो जोड़ी की दूरी के जोड़े का उपयोग करके सेट की जाती है और समन्वय के किसी दिए गए नंबर (पी) के प्रत्येक तत्व को जिम्मेदार ठहराया जाता है ताकि जोड़ी की संरचना हो इन सहायक निर्देशांक का उपयोग करके मापा गया तत्वों के बीच पारस्परिक दूरी औसतन, कम से कम निर्दिष्ट से भिन्न होती है। यह ध्यान दिया जाना चाहिए कि क्लस्टर-विश्लेषण और बहुआयामी स्केलिंग के मुख्य परिणाम और विधियां आमतौर पर स्रोत डेटा की संभाव्य प्रकृति की किसी भी धारणा के बिना विकसित होती हैं।
बहुआयामी सांख्यिकीय विश्लेषण का लागू उद्देश्य मुख्य रूप से निम्नलिखित तीन समस्याओं की सेवा में होता है।
विश्लेषण संकेतकों के बीच निर्भरताओं के सांख्यिकीय अध्ययन की समस्या। यह मानते हुए कि इन संकेतकों के सार्थक अर्थ और अध्ययन के अंतिम उद्देश्यों के आधार पर एक्स्बिट के सांख्यिकीय रूप से रिकॉर्ड किए गए संकेतकों का अध्ययन सेट, क्यू-मेर्नेन पर समर्थन (आश्रित) चर और (पीक्यू) -मेर-आयामी निलंबन (स्वतंत्र) चर, कहा जा सकता है कि समस्या अनुमत समाधान वर्ग से ऐसे क्यू-आयामी वेक्टर फ़ंक्शन के नमूने (1) के आधार पर निर्धारित करना है। एफ, के-पैराडियम एक निश्चित अर्थ में, संकेतकों के संकेतक के व्यवहार के अनुमान के बारे में सबसे अच्छा देगा। सन्निकटन और प्रकृति की गुणवत्ता की विशिष्टता के विशिष्ट प्रकार के आधार पर, विश्लेषण संकेतक उन या कई प्रतिगमन, फैलाव, कॉन्वर्सी या संघर्ष विश्लेषण की अन्य योजनाओं में आते हैं।
कुल (गैर-स्ट्रोक) फॉर्मूलेशन में तत्वों (वस्तुओं या संकेतकों) के वर्गीकरण की समस्या यह है कि तत्वों का पूरा विश्लेषण सेट, सांख्यिकीय रूप से एक मैट्रिक्स या मैट्रिक्स के रूप में दर्शाया गया है, को अपेक्षाकृत कम संख्या में विभाजित किया गया है सजातीय के, एक निश्चित अर्थ में, समूह। एक प्राथमिक जानकारी और विशिष्ट प्रकार की कार्यक्षमता की प्रकृति के आधार पर, जो वर्गीकरण गुणवत्ता मानदंड को निर्दिष्ट करता है, उन या अन्य योजनाओं के लिए आते हैं, क्लस्टर विश्लेषण (वर्गीकरण, छवि पहचान "शिक्षक के बिना"), विभाजन वितरण मिश्रण ।
फैक्टर स्पेस के तहत अध्ययन के आयाम को कम करने की समस्या और सबसे सूचनात्मक संकेतकों का चयन एक अपेक्षाकृत छोटी संख्या का एक सेट निर्धारित करना है, जो स्रोत संकेतकों के अनुमेय परिवर्तनों की श्रेणी में पाया जा सकता है। ![]() के-रोम (देखें) पर संकेतों की एम-आयामी प्रणाली की अनौपचारिकता के एक विशेष एक्सो-निर्दिष्ट उपाय का शीर्ष। ऑटोमोफॉर्मेटिविटी के माप को परिभाषित करने वाले कार्यात्मकता (यानी, सांख्यिकीय में निहित जानकारी के संरक्षण को अधिकतम करने के उद्देश्य से। स्रोत के सापेक्ष सरणी (1) स्वयं के सापेक्ष), विशेष रूप से, कारक विश्लेषण और मुख्य घटकों की विभिन्न योजनाओं के लिए , संकेतों के चरम संकेतों के तरीकों के लिए। बाहरी अनौपचारिकता के उपाय को परिभाषित करने के लिए, यानी, किसी अन्य व्यक्ति के सापेक्ष अधिकतम जानकारी (1) से निकालने के उद्देश्य से, एफ, सूचक या घटना में सीधे निहित नहीं है, सांख्यिकीय योजनाओं में सबसे सूचनात्मक संकेतकों के चयन के विभिन्न तरीकों का कारण बनता है। निर्भरता और भेदभाव विश्लेषण के अध्ययन।
के-रोम (देखें) पर संकेतों की एम-आयामी प्रणाली की अनौपचारिकता के एक विशेष एक्सो-निर्दिष्ट उपाय का शीर्ष। ऑटोमोफॉर्मेटिविटी के माप को परिभाषित करने वाले कार्यात्मकता (यानी, सांख्यिकीय में निहित जानकारी के संरक्षण को अधिकतम करने के उद्देश्य से। स्रोत के सापेक्ष सरणी (1) स्वयं के सापेक्ष), विशेष रूप से, कारक विश्लेषण और मुख्य घटकों की विभिन्न योजनाओं के लिए , संकेतों के चरम संकेतों के तरीकों के लिए। बाहरी अनौपचारिकता के उपाय को परिभाषित करने के लिए, यानी, किसी अन्य व्यक्ति के सापेक्ष अधिकतम जानकारी (1) से निकालने के उद्देश्य से, एफ, सूचक या घटना में सीधे निहित नहीं है, सांख्यिकीय योजनाओं में सबसे सूचनात्मक संकेतकों के चयन के विभिन्न तरीकों का कारण बनता है। निर्भरता और भेदभाव विश्लेषण के अध्ययन।
एम एस का मुख्य गणितीय वाद्य यंत्र। लेकिन अ। रैखिक समीकरणों की प्रणालियों और मैट्रिस के सिद्धांत के सिद्धांत के सिद्धांत (Eigenvalues \u200b\u200bऔर वैक्टर की एक सरल और सामान्यीकृत समस्या को हल करने के तरीके; matrices की सरल उपचार और छद्म बनाने; matrices, आदि के विकर्णकरण के लिए प्रक्रियाओं; ।) और कुछ अनुकूलन एल्गोरिदम (समन्वय वंशज संयुग्मित ग्रेडियेंट, शाखाओं और सीमाओं के तरीके, यादृच्छिक खोज और stochastich के विभिन्न संस्करण। सन्निकटन, आदि)।
लिट: एंडरसन टी।, बहुआयामी सांख्यिकीय विश्लेषण का परिचय, प्रति। अंग्रेजी से, एम।, 1 9 63; केंडल एम जे।, स्टौचर ए।, बहुआयामी सांख्यिकीय विश्लेषण और अस्थायी पंक्तियों, प्रति। अंग्रेजी से, एम।, 1 9 76; बोल्शेव एल एन।, "बुल। इंट। स्टेट। इंस्ट।", 1 9 6 9, नंबर 43, पी। 425-41; विशार्ट। जे।, "बायोमेट्रिका", 1 9 28, वी। 20 ए, पी। 32-52: होटेलिंग एच।, "एन। गणित। स्टेट।", 1 9 31, वी। 2, पी। 360-78; [में] क्रस्कल जे वी, "साइकोमेट्रिका", 1 9 64, वी। 29, पी। 1-27; Ivazyan एस ए, Bejaev 3. I., . Starovrov O. V., बहुआयामी टिप्पणियों का वर्गीकरण, एम, 1 9 74।
एस ए। Awazyan।
गणितीय विश्वकोष। - एम।: सोवियत एनसाइक्लोपीडिया। I. Vinogradov। 1977-1985।
तकनीकी अनुवादक निर्देशिकागणित के लिए समर्पित गणितीय आंकड़ों (देखें) का अनुभाग। अध्ययन के तहत बहुआयामी विशेषता के घटकों के बीच संबंधों की प्रकृति और संरचना की पहचान करने के उद्देश्य (देखें) और वैज्ञानिक प्राप्त करने के इरादे से। और व्यावहारिक। ... ...
एक व्यापक अर्थ में, गणितीय आंकड़ों का अनुभाग (गणितीय आंकड़े देखें), जो उन वस्तुओं से संबंधित सांख्यिकीय डेटा का अध्ययन करने के तरीकों को जोड़ता है जो कई उच्च गुणवत्ता वाले या मात्रात्मक द्वारा विशेषता हैं ... ... ग्रेट सोवियत एनसाइक्लोपीडिया
विश्लेषण बहुआयामी सांख्यिकीय - गणितीय आंकड़ों का अनुभाग, तीन और अधिक चर के बीच के लिंक का विश्लेषण करने के लिए डिज़ाइन किया गया है। आप सशर्त रूप से तीन मूल वर्ग कार्यों को आवंटित कर सकते हैं यह चर के बीच के लिंक की संरचना और अंतरिक्ष के आकार में कमी के एक अध्ययन का एक अध्ययन है ... समाजशास्त्र: विश्वकोष
Covariarce का विश्लेषण - - गणित के तरीकों का एक सेट। गैर-शांत कारकों के सेट से कुछ यादृच्छिक परिवर्तनीय वाई के औसत मूल्य के औसत मान के मॉडल के विश्लेषण से संबंधित आंकड़े और एक साथ मात्रात्मक कारकों एक्स के सेट से। वाई के संबंध में ... ... रूसी समाजशास्त्रीय विश्वकोष
अनुभाग गणित। सांख्यिकी, आरवाईओ की सामग्री सांख्यिकीय विकास और अध्ययन है। भेद (भेदभाव) की निम्नलिखित समस्या को हल करने के तरीके: अवलोकनों के परिणामों के आधार पर, निर्धारित करें कि कई संभव ... ... गणितीय विश्वकोष, ऑर्लोवा इरीना वैलेनोवना, अंत नताल्या वैलेरिवना, टुरुनुनावेस्की विक्टर बोरिसोविच। पुस्तक बहुआयामी सांख्यिकीय विश्लेषण (एमएसए) और एमईएस पर गणना के संगठन के लिए समर्पित है। बहुआयामी सांख्यिकी विधियों को लागू करने के लिए, प्रोग्रामर का उपयोग सांख्यिकीय किया जाता है ...
बहुआयामी सांख्यिकीय विश्लेषण का उपयोग निम्नलिखित कार्यों को हल करने में किया जाता है:
- * संकेतों के बीच संबंधों का अध्ययन;
- * वैक्टर द्वारा निर्दिष्ट वस्तुओं या संकेतों का वर्गीकरण;
- * संकेतों के संकेतों के आयाम को कम करना।
इस मामले में, अवलोकनों का परिणाम ऑब्जेक्ट पर मापा गया मात्रात्मक और कभी-कभी उच्च गुणवत्ता वाले संकेतों के मूल्यों का वेक्टर है। मात्रात्मक सुविधा देखी गई इकाई का एक संकेत है, जिसे सीधे माप की संख्या और इकाई द्वारा व्यक्त किया जा सकता है। मात्रात्मक सुविधा एक गुणात्मक का विरोध करती है - मनाई गई इकाई का संकेत, दो या दो से अधिक सशर्त श्रेणियों में से एक के लिए असाइनमेंट द्वारा निर्धारित (यदि वास्तव में दो श्रेणियां हैं, तो संकेत को वैकल्पिक कहा जाता है)। उच्च गुणवत्ता वाले संकेतों का सांख्यिकीय विश्लेषण गैर-प्रकृति की वस्तुओं के आंकड़ों का हिस्सा है। मात्रात्मक सुविधाओं को अंतराल तराजू, रिश्तों, मतभेदों, पूर्ण में मापा गया संकेतों में विभाजित किया जाता है।
और उच्च गुणवत्ता - नाम पैमाने और क्रमिक पैमाने में मापा संकेतों पर। डेटा प्रोसेसिंग विधियों को स्केल के साथ समन्वित किया जाना चाहिए जिसमें विचाराधीन संकेत मापा जाता है।
संकेतों के बीच संबंधों के अध्ययन के उद्देश्य संकेतों और इस संबंध के अध्ययन के बीच संचार की उपलब्धता का सबूत हैं। दो यादृच्छिक एक्स और वाई के बीच बंधन की उपलब्धता को साबित करने के लिए, सहसंबंध विश्लेषण का उपयोग किया जाता है। यदि संयुक्त वितरण एक्स और वाई सामान्य है, तो सांख्यिकीय निष्कर्ष रैखिक सहसंबंध के एक चुनिंदा गुणांक पर आधारित होते हैं, अन्य मामलों में केंडल्ला और स्पिरमील रैंक सहसंबंध गुणांक के गुणांक का उपयोग करते हैं, और उच्च गुणवत्ता वाले संकेतों के लिए - ची के मानदंड- वर्ग।
प्रतिगमन विश्लेषण का उपयोग मात्रात्मक संकेतों की कार्यात्मक निर्भरता का अध्ययन करने के लिए किया जाता है मात्रात्मक संकेत x (1), x (2), ..., x (के)। इस निर्भरता को रिग्रेशन या संक्षेप में, प्रतिगमन कहा जाता है। प्रतिगमन विश्लेषण का सबसे सरल संभाव्यता मॉडल (के \u003d 1 के मामले में) प्रारंभिक जानकारी के रूप में उपयोग करता है अवलोकनों (xi, yi), i \u003d 1, 2, ..., एन, और उपस्थिति के एक सेट का उपयोग करता है
यी \u003d एक्सी + बी + ईआई, i \u003d 1, 2, ..., एन,
जहां ईआई - अवलोकन त्रुटियां। कभी-कभी यह माना जाता है कि ईआई एक ही सामान्य वितरण एन (0, यू 2) के साथ स्वतंत्र यादृच्छिक चर है। चूंकि अवलोकन त्रुटियों का वितरण आमतौर पर सामान्य से अलग होता है, इसलिए सलाह दी जाती है कि गैर-पैरामीट्रिक फॉर्मूलेशन में रिग्रेशन मॉडल पर विचार करें, यानी। ईआई के मनमाने ढंग से वितरण के साथ।
प्रतिगमन विश्लेषण का मुख्य कार्य अज्ञात पैरामीटर ए और बी का आकलन करना है, जो एक्स के रैखिक निर्भरता वाई को निर्दिष्ट करता है। इस समस्या को हल करने के लिए, इसका उपयोग अभी भी 17 9 4 में के गॉस द्वारा किया जाता है। कम से कम वर्ग विधि, यानी वर्गों के योग को कम करने के लिए शर्तों से अज्ञात मॉडल पैरामीटर और बी के अनुमान खोजें
एक और बी वैकल्पिक।
फैलाव विश्लेषण का उपयोग मात्रात्मक चर पर उच्च गुणवत्ता वाले संकेतों के प्रभाव का अध्ययन करने के लिए किया जाता है। उदाहरण के लिए, के मशीनों पर जारी उत्पादों की इकाइयों की गुणवत्ता के मात्रात्मक संकेतक के माप परिणामों के के नमूने को दें, यानी। संख्याओं का सेट (x1 (j), x2 (j), ..., xn (j)), जहां जे मशीन संख्या है, जे \u003d 1, 2, ..., के, और एन - का आकार नमूना। फैलाव विश्लेषण के सामान्य फॉर्मूलेशन में, यह माना जाता है कि माप के परिणाम स्वतंत्र होते हैं और प्रत्येक नमूने में एक ही फैलाव के साथ एक सामान्य वितरण एन (एम (जे), यू 2) होता है।
उत्पाद की गुणवत्ता की एकरूपता की जांच, यानी। उत्पादों की गुणवत्ता पर मशीन की संख्या के प्रभाव की कमी परिकल्पना की जांच के लिए कम हो जाती है
एच 0: एम (1) \u003d एम (2) \u003d ... \u003d एम (के)।
फैलाव विश्लेषण ने इस तरह के परिकल्पनाओं की पुष्टि के लिए तरीकों का विकास किया।
Hypothesis H0 वैकल्पिक परिकल्पना एच 1 के खिलाफ परीक्षण किया जाता है, जिसके अनुसार इनमें से कम से कम एक समीकरण पूरा नहीं हुआ है। इस परिकल्पना का सत्यापन निम्नलिखित "फैलाव अपघटन" पर आधारित है जो आरए द्वारा इंगित किया गया है। फिशर:
जहां एस 2 संयुक्त नमूने में एक चुनिंदा फैलाव है, यानी
इस प्रकार, सूत्र (7) के दाहिने हाथ की पहली अवधि इंट्राग्रुप फैलाव को दर्शाती है। अंत में, इंटरग्रुप फैलाव,
फॉर्मूला (7) के प्रकार के फैलाव अपघटन से जुड़े आवेदन आंकड़ों का दायरा फैलाव विश्लेषण कहा जाता है। फैलाव विश्लेषण समस्या के उदाहरण के रूप में, हम इस धारणा के तहत उपर्युक्त एच 0 परिकल्पना के परीक्षण पर विचार करते हैं कि माप के परिणाम स्वतंत्र हैं और प्रत्येक नमूने में एक सामान्य वितरण एन (एम (जे), यू 2) एक ही फैलाव के साथ है । एच 0 के न्याय के साथ, यू 2 द्वारा विभाजित सूत्र (7) के दाहिने हाथ की पहली अवधि में के (एन -1) स्वतंत्रता की डिग्री के साथ एक ची-वर्ग वितरण होता है, और यू 2 द्वारा विभाजित दूसरी अवधि भी होती है एक ची-स्क्वायर वितरण, लेकिन स्वतंत्रता की डिग्री (के -1) डिग्री के साथ, और पहली और दूसरी शर्तें यादृच्छिक चर के रूप में स्वतंत्र हैं। इसलिए, एक यादृच्छिक राशि

इसमें संख्यात्मक की स्वतंत्रता की स्वतंत्रता की स्वतंत्रता और के (एन -1) डिग्री की स्वतंत्रता की डिग्री (के -1) डिग्री के साथ फिशर का वितरण है। Hypothesis H0 स्वीकार किया जाता है अगर एफ< F1-б, и отвергается в противном случае, где F1-б - квантиль порядка 1-б распределения Фишера с указанными числами степеней свободы. Такой выбор критической области определяется тем, что при Н1 величина F безгранично увеличивается при росте объема выборок n. Значения F1-б берут из соответствующих таблиц.
फैलाव विश्लेषण की शास्त्रीय समस्याओं को हल करने के अनमिमेट्रिक तरीकों, विशेष रूप से, परीक्षण hypothesis h0 विकसित किए गए थे।
बहुआयामी सांख्यिकीय विश्लेषण के निम्नलिखित प्रकार के कार्य - वर्गीकरण कार्य। उन्हें तीन मूलभूत रूप से विभिन्न प्रकारों में विभाजित किया गया है - भेदभाव विश्लेषण, क्लस्टर विश्लेषण, समूह कार्य।
भेदभावपूर्ण विश्लेषण का कार्य मनाए गए ऑब्जेक्ट को पहले वर्णित कक्षाओं में से एक में असाइन करने का नियम ढूंढना है। इस मामले में, ऑब्जेक्ट्स को वैक्टर का उपयोग करके गणितीय मॉडल में वर्णित किया जाता है जिनके निर्देशांक प्रत्येक ऑब्जेक्ट से कई संकेतों को देखने के परिणाम हैं। कक्षाओं को या तो सीधे गणितीय शब्दों में या प्रशिक्षण नमूने का उपयोग करके वर्णित किया गया है। प्रशिक्षण नमूना एक नमूना है, जिसके लिए प्रत्येक तत्व के लिए यह संकेत दिया जाता है कि यह किस वर्ग को संदर्भित करता है।
तकनीकी निदान में निर्णय लेने के लिए एक भेदभाव विश्लेषण लागू करने के एक उदाहरण पर विचार करें। कई उत्पाद पैरामीटर के माप के परिणामों को दें, दोषों की उपस्थिति या अनुपस्थिति को स्थापित करना आवश्यक है। इस मामले में, प्रशिक्षण नमूने के तत्व एक अतिरिक्त अध्ययन के दौरान किए गए दोषों का पता लगाया जाता है, उदाहरण के लिए, ऑपरेशन की एक निश्चित अवधि के बाद किया जाता है। भेदभाव विश्लेषण आपको नियंत्रण की मात्रा को कम करने के साथ-साथ उत्पादों के भविष्य के व्यवहार की भविष्यवाणी करने की अनुमति देता है। भेदभाव विश्लेषण प्रतिगमन के समान है - पहला आपको गुणात्मक सुविधा के मूल्य की भविष्यवाणी करने की अनुमति देता है, और दूसरा - मात्रात्मक। गैर-नाममात्र प्रकृति की वस्तुओं के आंकड़ों में, एक गणितीय योजना विकसित की गई है, जो रिग्रेशन और भेदभावपूर्ण परीक्षणों के विशेष मामले हैं।
क्लस्टर विश्लेषण का उपयोग तब किया जाता है जब सांख्यिकीय डेटा पर नमूना के तत्वों को समूह में विभाजित करना आवश्यक है। इसके अलावा, एक ही समूह से समूह के दो तत्वों को मापा गया संकेतों के मूल्यों के सेट द्वारा "बंद" होना चाहिए, और विभिन्न समूहों के दो तत्व एक ही अर्थ में "दूर" होना चाहिए। भेदभावपूर्ण विश्लेषण के विपरीत, कक्षाएं विश्लेषण क्लस्टर में निर्दिष्ट नहीं हैं, और सांख्यिकीय डेटा की प्रसंस्करण के दौरान गठित हैं। उदाहरण के लिए, एक क्लस्टर विश्लेषण को अपने आप के समूहों में इस्पात ग्रेड (या रेफ्रिजरेटर के ब्रांड) की कुलता को विभाजित करने के लिए लागू किया जा सकता है।
एक और प्रकार का क्लस्टर विश्लेषण प्रियजनों के समूहों के संकेतों का विभाजन है। संकेतों की निकटता का एक संकेतक सहसंबंध के एक चुनिंदा गुणांक के रूप में कार्य कर सकता है। संकेतों के लक्षणीकरण क्लस्टर का उद्देश्य नियंत्रित पैरामीटर की संख्या में कमी हो सकती है, जो नियंत्रण लागत को काफी कम करना संभव बनाता है। इसके लिए, निकट से संबंधित सुविधाओं के समूह से (जिसमें सहसंबंध गुणांक उसके अधिकतम मूल्य पर 1 के करीब है) एक के मूल्य को मापता है, और शेष मानों की गणना प्रतिगमन विश्लेषण का उपयोग करके की जाती है।
समूह के कार्य तय कर रहे हैं कि कक्षाएं पहले से निर्दिष्ट नहीं हैं और एक दूसरे से "दूर" होने के लिए बाध्य नहीं हैं। एक उदाहरण अध्ययन समूहों पर छात्रों का समूह है। समूह की समस्या को हल करने वाली तकनीक अक्सर एक पैरामीट्रिक श्रृंखला होती है - संभावित आकार पैरामीट्रिक श्रृंखला के तत्वों के अनुसार समूहीकृत होते हैं। साहित्य में, आवेदन आंकड़ों पर नियामक और तकनीकी और दिशानिर्देश दस्तावेज, अवलोकन परिणामों का एक समूह कभी-कभी उपयोग किया जाता है (उदाहरण के लिए, हिस्टोग्राम बनाने के दौरान)।
वर्गीकरण के कार्य न केवल बहुआयामी सांख्यिकीय विश्लेषण में हल किए जाते हैं, बल्कि जब अवलोकन के परिणाम संख्या, कार्य या गैर-प्रकृति के ऑब्जेक्ट होते हैं। इस प्रकार, कई क्लस्टर विश्लेषण एल्गोरिदम वस्तुओं के बीच केवल दूरी का उपयोग करते हैं। इसलिए, उन्हें गैर-प्रकृति की वस्तुओं के वर्गीकरण पर भी लागू किया जा सकता है, अगर उनके बीच केवल दूरी निर्धारित की गई थी। वर्गीकरण का सबसे आसान कार्य निम्नानुसार है: दो स्वतंत्र नमूने दिए जाते हैं, यह निर्धारित करने के लिए आवश्यक है, वे दो वर्गों या एक का प्रतिनिधित्व करते हैं। एक-आयामी आंकड़ों में, यह कार्य एकरूपता परिकल्पना की जांच के लिए कम हो गया है।
बहुआयामी सांख्यिकीय विश्लेषण का तीसरा खंड कम आयाम (सूचना के संपीड़न) का कार्य है। उनके समाधान का लक्ष्य प्रारंभिक संकेतों के परिवर्तन से प्राप्त डेरिवेटिव के सेट को निर्धारित करना है, जैसे कि डेरिवेटिव्स की संख्या स्रोत संकेतों की संख्या से काफी कम है, लेकिन उनमें स्रोत सांख्यिकीय डेटा में उपलब्ध अधिकांश जानकारी शामिल है । आयाम में कमी के कार्यों को बहुआयामी पैमाने के तरीकों, मुख्य घटकों, कारक विश्लेषण इत्यादि का उपयोग करके हल किया जाता है। उदाहरण के लिए, बहुआयामी स्केलिंग के सबसे सरल मॉडल में, प्रारंभिक डेटा के ऑब्जेक्ट्स के बीच जोड़ी की दूरी है, और गणना का उद्देश्य प्रतिनिधित्व करना है ऑब्जेक्ट्स प्लेन पर अंक। यह यह देखने के लिए शब्द की शाब्दिक अर्थ में संभव बनाता है कि वस्तुएं एक-दूसरे से कैसे संबंधित हैं। इस लक्ष्य को प्राप्त करने के लिए, प्रत्येक ऑब्जेक्ट को विमान पर बिंदु का अनुपालन करना आवश्यक है ताकि युग्मित दूरी की संख्या और जे के साथ वस्तुओं से संबंधित बिंदुओं के बीच एसईजे, इनमें से एसआईजेडी की दूरी को और अधिक सटीक रूप से पुन: उत्पन्न करना संभव है वस्तुओं। कम से कम वर्ग विधि के मूल विचार के अनुसार, विमान पर अंक हैं ताकि परिमाण
अपने सबसे छोटे मूल्य तक पहुँच गया। डेटा के आयाम और दृश्यता को कम करने के लिए कई अन्य सेटिंग्स हैं।
संभाव्यता गणितीय सांख्यिकी गुणवत्ता
सामाजिक और आर्थिक वस्तुओं को आमतौर पर बहुआयामी वैक्टर बनाने के लिए पर्याप्त रूप से बड़ी संख्या में मापदंडों की विशेषता होती है, और इन वैक्टरों के घटकों के बीच संबंधों का अध्ययन करने के कार्य आर्थिक और सामाजिक अध्ययन में विशेष रूप से महत्वपूर्ण होते हैं, और इन संबंधों को आधार पर पता लगाने की आवश्यकता होती है एक सीमित संख्या में बहुआयामी अवलोकन।
एक बहुआयामी सांख्यिकीय विश्लेषण को गणितीय सांख्यिकी अनुभाग कहा जाता है, जो बहुआयामी सांख्यिकीय डेटा, उनके व्यवस्थापन और प्रसंस्करण के तरीकों का अध्ययन करता है, जिसमें बहुआयामी सुविधा के अध्ययन के घटकों के बीच संबंधों की प्रकृति और संरचना की पहचान करने के लिए, प्राप्त करना, प्राप्त करना व्यावहारिक निष्कर्ष।
ध्यान दें कि डेटा संग्रह विधियां भिन्न हो सकती हैं। इसलिए, यदि वैश्विक अर्थव्यवस्था की जांच की जाती है, तो उन वस्तुओं के रूप में लेना स्वाभाविक होता है जिन पर वेक्टर एक्स के मूल्य, देश को देखा जाता है, अगर राष्ट्रीय आर्थिक प्रणाली का अध्ययन किया जाता है, तो स्वाभाविक रूप से एक्स वेक्टर के अर्थों का पालन करते हैं समय पर विभिन्न बिंदुओं पर वही (शोधकर्ता के लिए ब्याज)।
कई सहसंबंध और प्रतिगमन विश्लेषण जैसे सांख्यिकीय तरीकों पर पारंपरिक रूप से संभाव्यता और गणितीय आंकड़ों के सिद्धांत के पाठ्यक्रमों में अध्ययन किया जाता है, अनुशासन "अर्थमितीय" प्रतिगमन विश्लेषण के लागू पहलुओं पर विचार करने के लिए समर्पित है।
सांख्यिकीय डेटा के आधार पर बहुआयामी सामान्य समेकन का अध्ययन करने के लिए एक और तरीका इस मैनुअल को समर्पित है।
बहुआयामी अंतरिक्ष की कमी के आयाम की कमी, सूचना के महत्वपूर्ण नुकसान के बिना, बड़ी संख्या में देखी गई अंतःस्थापित कारकों की प्रारंभिक प्रणाली को छिपे हुए (असंबद्ध) कारकों की काफी छोटी संख्या की प्रणाली में स्थानांतरित करें जो भिन्नता निर्धारित करते हैं प्रारंभिक संकेत। पहला अध्याय घटक और कारक विश्लेषण के तरीकों का वर्णन करता है, जिसका उपयोग आप निष्पक्ष रूप से मौजूदा पहचान सकते हैं, लेकिन मुख्य घटकों या कारकों की सहायता से सीधे पैटर्न नहीं देख सकते हैं।
बहुआयामी वर्गीकरण के तरीकों का उद्देश्य वस्तुओं के सेट (बड़ी संख्या में सुविधाओं द्वारा विशेषता) को कक्षाओं में अलग करना है, जिनमें से प्रत्येक में वस्तुओं को एक निश्चित अर्थ, सजातीय या रिश्तेदारों में शामिल करना चाहिए। ऑब्जेक्ट्स पर सुविधाओं के मूल्यों पर सांख्यिकीय डेटा के आधार पर यह वर्गीकरण दूसरे अध्याय ("सांख्यिकी" का उपयोग करके बहुआयामी सांख्यिकीय विश्लेषण) में माना जाने वाला क्लस्टर और भेदभाव विश्लेषण के तरीकों से किया जा सकता है।
कंप्यूटिंग उपकरण और सॉफ्टवेयर का विकास बहुआयामी सांख्यिकीय विश्लेषण विधियों के व्यापक परिचय में योगदान देता है। एक सुविधाजनक यूजर इंटरफेस के साथ अनुप्रयोग कार्यक्रमों के पैकेज, जैसे कि एसपीएसएस, सांख्यिकी, एसएएस इत्यादि, इन तरीकों के आवेदन में कठिनाइयों को हटा दें, जिसमें रैखिक बीजगणित, संभावनाओं के सिद्धांत के आधार पर गणितीय उपकरण की जटिलता शामिल है और गणितीय आंकड़े, और बोझिल गणना।
हालांकि, एल्गोरिदम के गणितीय सार की समझ के बिना कार्यक्रमों का उपयोग बहुतायतवादी सांख्यिकीय तरीकों के उपयोग की सादगी के भ्रम के विकास में योगदान देता है, जो गलत या अनुचित परिणामों का कारण बन सकता है। महत्वपूर्ण व्यावहारिक परिणाम केवल विषय क्षेत्र में पेशेवर ज्ञान के आधार पर प्राप्त किए जा सकते हैं, गणितीय विधियों और अनुप्रयोग संकुलों के कब्जे से प्रबलित किए जाते हैं जिसमें इन विधियों को लागू किया जाता है।
इसलिए, इस पुस्तक में विचाराधीन प्रत्येक विधियों के लिए, मुख्य सैद्धांतिक जानकारी प्रदान की जाती है, जिसमें एल्गोरिदम शामिल हैं; आवेदन पैकेजों में इन विधियों और एल्गोरिदम के कार्यान्वयन पर चर्चा की गई है। विचाराधीन विधियों को एसपीएसएस पैकेज का उपयोग करके अर्थव्यवस्था में उनके व्यावहारिक अनुप्रयोग के उदाहरणों से सचित्र किया गया है।
मैनुअल प्रबंधन के राज्य विश्वविद्यालय के छात्रों "बहुआयामी सांख्यिकीय तरीकों" छात्रों को पढ़ने के अनुभव के आधार पर लिखा गया है। लागू बहुआयामी सांख्यिकीय विश्लेषण के तरीकों के अधिक विस्तृत अध्ययन के लिए, किताबों की सिफारिश की जाती है।
यह माना जाता है कि पाठक एक रैखिक बीजगणित के पाठ्यक्रमों से परिचित है (उदाहरण के लिए, पाठ्यपुस्तक के दायरे में और पाठ्यपुस्तक के लिए अनुलग्नक), संभावनाओं और गणितीय आंकड़ों का सिद्धांत (उदाहरण के लिए, पाठ्यपुस्तक की मात्रा में )।