Analisisnya adalah statistik multivariat. Pengantar Analisis Statistik Multivariat - Estimasi Fungsi Prediktif Linear Kalinina
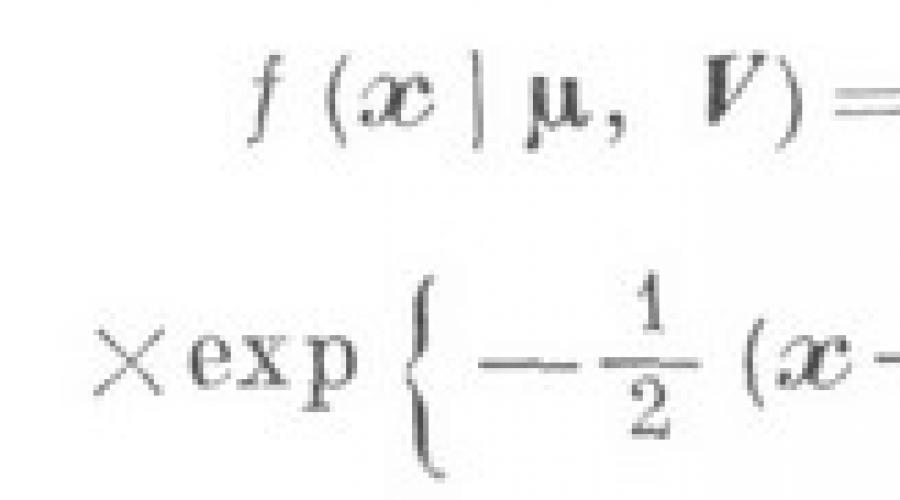
Baca juga
Ada situasi di mana variabilitas acak diwakili oleh satu atau dua variabel acak, tanda.
Misalnya, saat mempelajari populasi statistik orang, kami tertarik pada tinggi dan berat badan. Dalam situasi ini, tidak peduli berapa banyak orang yang ada dalam populasi statistik, kami selalu dapat memplot sebar dan melihat keseluruhan gambar. Namun, jika ada tiga fitur, misalnya ditambahkan fitur - usia seseorang, maka scatterplot harus dibangun dalam ruang tiga dimensi. Merepresentasikan sekumpulan titik dalam ruang tiga dimensi sudah cukup sulit.
Pada kenyataannya, dalam praktiknya, setiap pengamatan diwakili bukan oleh satu, dua, atau tiga angka, tetapi oleh beberapa rangkaian angka yang terlihat yang menggambarkan lusinan fitur. Dalam situasi ini, untuk membuat scatterplot, perlu mempertimbangkan ruang multidimensi.
Cabang statistik yang dikhususkan untuk mempelajari eksperimen dengan pengamatan multivariat disebut analisis statistik multivariat.
Pengukuran beberapa fitur (properti suatu objek) sekaligus dalam satu percobaan umumnya lebih alami daripada pengukuran satu atau dua. Oleh karena itu, analisis statistik multivariat yang berpotensi memiliki bidang aplikasi yang luas.
Analisis statistik multivariat mencakup bagian berikut:
Analisis faktor;
Analisis diskriminan;
analisis klaster;
Penskalaan multidimensi;
Metode kontrol kualitas.
Analisis faktor
Dalam studi tentang objek dan sistem yang kompleks (misalnya, dalam psikologi, biologi, sosiologi, dll.), Kuantitas (faktor) yang menentukan sifat-sifat objek tersebut sangat sering tidak dapat diukur secara langsung, dan terkadang bahkan jumlah dan maknanya. tidak diketahui. Tetapi kuantitas lain mungkin tersedia untuk pengukuran, dengan satu atau lain cara tergantung pada faktor yang diminati. Selain itu, ketika pengaruh faktor kepentingan yang tidak diketahui bagi kita memanifestasikan dirinya dalam beberapa fitur yang diukur, fitur ini dapat menunjukkan hubungan yang erat satu sama lain dan jumlah faktor bisa jauh lebih sedikit daripada jumlah variabel yang diukur.
Metode analisis faktor digunakan untuk mengidentifikasi faktor-faktor yang mempengaruhi variabel yang diukur.
Contoh penggunaan analisis faktor adalah studi tentang ciri-ciri kepribadian berdasarkan tes psikologi. Properti kepribadian tidak dapat menerima pengukuran langsung, mereka hanya dapat dinilai dari perilaku seseorang atau sifat dari jawaban atas pertanyaan tertentu. Untuk menjelaskan hasil eksperimen, mereka dikenai analisis faktor, yang memungkinkan untuk mengidentifikasi sifat-sifat pribadi yang memengaruhi perilaku individu yang diuji.
Berbagai model analisis faktor didasarkan pada hipotesis berikut: parameter yang diamati atau diukur hanyalah karakteristik tidak langsung dari objek atau fenomena yang dipelajari; bahkan ada yang internal (tersembunyi, terpendam, tidak dapat diamati secara langsung) parameter dan properti, yang jumlahnya kecil dan yang menentukan nilai parameter yang diamati. Parameter internal ini disebut faktor.
Tugas analisis faktoradalah representasi dari parameter yang diamati dalam bentuk kombinasi linear dari faktor-faktor dan, mungkin, beberapa gangguan tambahan yang tidak signifikan.
Tahap pertama analisis faktor, sebagai aturan, adalah pemilihan fitur baru, yang merupakan kombinasi linier dari yang sebelumnya dan "menyerap" sebagian besar variabilitas total data yang diamati, dan karenanya menyampaikan sebagian besar informasi yang terkandung dalam pengamatan asli. Ini biasanya dilakukan dengan menggunakan metode komponen utama, meskipun terkadang teknik lain digunakan (metode kemungkinan maksimum).
Metode komponen utama direduksi menjadi pilihan sistem koordinat ortogonal baru di ruang observasi. Arah sepanjang larik pengamatan memiliki sebaran terbesar dipilih sebagai komponen utama pertama, setiap komponen utama berikutnya dipilih sehingga sebaran pengamatan maksimum dan komponen utama ini ortogonal terhadap komponen utama lainnya yang dipilih sebelumnya. Namun, faktor-faktor yang diperoleh dengan metode komponen utama biasanya tidak memberikan interpretasi visual yang memadai. Oleh karena itu, langkah selanjutnya dalam analisis faktor adalah transformasi, rotasi faktor untuk memudahkan interpretasi.
Analisis Diskriminan
Misalkan ada sekumpulan objek yang dibagi menjadi beberapa grup, dan untuk setiap objek dimungkinkan untuk menentukan grup mana yang termasuk. Untuk setiap objek ada pengukuran beberapa karakteristik kuantitatif. Penting untuk menemukan cara bagaimana, berdasarkan karakteristik ini, Anda dapat mengetahui grup tempat objek tersebut berada. Ini akan memungkinkan Anda untuk menentukan grup tempat objek baru dari koleksi yang sama berada. Untuk mengatasi masalah, terapkan metode analisis diskriminan.
Analisis Diskriminan- ini adalah bagian statistika yang isinya adalah pengembangan metode pemecahan masalah pembedaan (diskriminasi) objek pengamatan menurut ciri-ciri tertentu.
Mari kita lihat beberapa contoh.
Analisis diskriminan terbukti berguna dalam menangani hasil tes individu ketika harus merekrut untuk posisi tertentu. Dalam hal ini, semua kandidat perlu dibagi menjadi dua kelompok: "cocok" dan "tidak cocok".
Penggunaan analisis diskriminan dimungkinkan oleh administrasi perbankan untuk menilai keadaan keuangan klien ketika mengeluarkan pinjaman kepada mereka. Bank, menurut sejumlah fitur, mengklasifikasikannya menjadi dapat diandalkan dan tidak dapat diandalkan.
Analisis diskriminan dapat digunakan sebagai metode untuk membagi sekumpulan perusahaan menjadi beberapa kelompok homogen sesuai dengan nilai indikator produksi dan kegiatan ekonomi apa pun.
Metode analisis diskriminan memungkinkan untuk membangun fungsi dari karakteristik yang diukur, yang nilainya menjelaskan pembagian objek menjadi beberapa kelompok. Diinginkan bahwa fungsi-fungsi ini (fitur pembeda) sedikit. Dalam hal ini, hasil analisis lebih mudah ditafsirkan secara bermakna.
Karena kesederhanaannya, analisis diskriminan linier memainkan peran khusus, di mana fitur klasifikasi dipilih sebagai fungsi linier dari fitur utama.
analisis klaster
Metode analisis cluster memungkinkan untuk membagi kumpulan objek yang dipelajari menjadi kelompok objek "serupa", yang disebut cluster.
Kata gugus asal bahasa Inggris - cluster diterjemahkan sebagai kuas, gerombolan, kelompok, gerombolan, gerombolan.
Analisis klaster menyelesaikan tugas-tugas berikut:
Lakukan klasifikasi objek, dengan mempertimbangkan semua fitur yang menjadi ciri objek tersebut. Kemungkinan klasifikasi membawa kita ke pemahaman yang lebih dalam tentang totalitas yang dipertimbangkan dan objek yang termasuk di dalamnya;
Menetapkan tugas untuk memeriksa keberadaan struktur atau klasifikasi yang diberikan secara apriori dalam populasi yang ada. Verifikasi semacam itu memungkinkan untuk menggunakan skema penelitian ilmiah hipotetis-deduktif standar.
Sebagian besar metode pengelompokan (grup hierarkis) adalah aglomerasi(pemersatu) - mereka mulai dengan pembuatan cluster dasar, yang masing-masing terdiri dari tepat satu pengamatan awal (satu titik), dan pada setiap langkah berikutnya, dua cluster terdekat digabungkan menjadi satu.
Momen penghentian proses ini dapat diatur oleh peneliti (misalnya, dengan menentukan jumlah cluster yang diperlukan atau jarak maksimum yang dicapai penyatuan).
Representasi grafis dari proses penggabungan cluster dapat diperoleh dengan menggunakan dendrogram- pohon serikat klaster.
Perhatikan contoh berikut. Mari kita mengklasifikasikan lima perusahaan, yang masing-masing dicirikan oleh tiga variabel:
x 1– biaya tahunan rata-rata aset produksi tetap, miliar rubel;
x 2- biaya material per 1 gosok. produk manufaktur, kop.;
x 3- volume produk manufaktur, miliar rubel.
Pengenalan PC dalam manajemen ekonomi nasional melibatkan transisi dari metode tradisional untuk menganalisis aktivitas perusahaan ke model manajemen ekonomi yang lebih maju, yang memungkinkan pengungkapan proses yang mendalam.
Meluasnya penggunaan metode statistik matematika dalam penelitian ekonomi memungkinkan untuk memperdalam analisis ekonomi, meningkatkan kualitas informasi dalam perencanaan dan peramalan indikator produksi dan menganalisis keefektifannya.
Kompleksitas dan variasi hubungan antara indikator ekonomi menentukan fitur multidimensi dan, oleh karena itu, memerlukan penggunaan perangkat matematika yang paling kompleks - metode analisis statistik multivariat.
Konsep "analisis statistik multivariat" menyiratkan kombinasi sejumlah metode yang dirancang untuk mengeksplorasi kombinasi fitur yang saling terkait. Kita berbicara tentang pemotongan (partisi) dari himpunan yang dipertimbangkan, yang diwakili oleh fitur multidimensi menjadi jumlah yang relatif kecil.
Pada saat yang sama, transisi dari sejumlah besar fitur ke fitur yang lebih kecil bertujuan untuk mengurangi dimensinya dan meningkatkan kapasitas informasinya. Tujuan ini dicapai dengan mengidentifikasi informasi yang berulang, dihasilkan oleh fitur yang saling terkait, menetapkan kemungkinan agregasi (menggabungkan, menjumlahkan) menurut beberapa fitur. Yang terakhir melibatkan transformasi model aktual menjadi model dengan fitur faktor yang lebih sedikit.
Metode analisis statistik multidimensi memungkinkan untuk mengidentifikasi pola yang ada secara objektif, tetapi tidak diungkapkan secara eksplisit, yang memanifestasikan dirinya dalam fenomena sosial-ekonomi tertentu. Ini harus dihadapi ketika menyelesaikan sejumlah masalah praktis di bidang ekonomi. Secara khusus, hal di atas terjadi jika perlu mengakumulasi (memperbaiki) secara bersamaan nilai-nilai beberapa karakteristik kuantitatif (fitur) untuk objek pengamatan yang diteliti, ketika setiap karakteristik rentan terhadap variasi yang tidak terkendali (dalam konteks objek ), terlepas dari homogenitas objek pengamatan.
Misalnya, ketika memeriksa perusahaan yang homogen (dalam hal kondisi alam dan ekonomi dan jenis spesialisasi) dalam kaitannya dengan sejumlah indikator efisiensi produksi, kami yakin bahwa ketika berpindah dari satu objek ke objek lain, hampir setiap karakteristik yang dipilih ( identik) memiliki nilai numerik yang tidak sama, yaitu, ia menemukan, boleh dikatakan, pencar yang tidak terkendali (acak). Variasi "acak" dari sifat-sifat tersebut cenderung mengikuti beberapa kecenderungan (biasa), baik dalam hal dimensi sifat-sifat yang terdefinisi dengan baik di sekitar tempat terjadinya variasi, maupun dalam hal tingkat dan saling ketergantungan variasi itu sendiri.
Hal tersebut di atas mengarah pada definisi variabel acak multidimensi sebagai sekumpulan fitur kuantitatif, yang nilainya masing-masing tunduk pada penyebaran yang tidak terkendali selama pengulangan proses ini, pengamatan statistik, pengalaman, eksperimen, dll.
Sebelumnya dikatakan bahwa analisis multivariat menggabungkan sejumlah metode; sebut saja mereka: analisis faktor, analisis komponen utama, analisis kluster, pengenalan pola, analisis diskriminan, dll. Tiga pertama dari metode ini dipertimbangkan dalam paragraf berikut.
Seperti metode matematika dan statistik lainnya, analisis multivariat dapat efektif dalam penerapannya, asalkan informasi awal berkualitas tinggi dan data pengamatannya masif dan diproses menggunakan PC.
Konsep dasar metode analisis faktor, inti dari tugas yang diselesaikannya
Ketika menganalisis (dan mempelajari secara setara) fenomena sosial-ekonomi, seseorang sering menjumpai kasus ketika, di antara keragaman (parametrisitas yang kaya) objek pengamatan, perlu untuk mengecualikan sebagian parameter, atau menggantinya dengan sejumlah kecil fungsi tertentu. tanpa merusak keutuhan (kelengkapan) informasi. Solusi dari masalah semacam itu masuk akal dalam kerangka model tertentu dan ditentukan oleh strukturnya. Contoh model seperti itu, yang paling cocok untuk banyak situasi nyata, adalah model analisis faktor, metode yang memungkinkan Anda memusatkan fitur (informasi tentangnya) dengan "memadatkan" sejumlah besar menjadi lebih kecil, lebih informatif. . Dalam hal ini, "kondensat" informasi yang diperoleh harus diwakili oleh karakteristik kuantitatif yang paling signifikan dan menentukan.
Konsep "analisis faktor" tidak boleh disamakan dengan konsep analisis kausal yang luas saat mempelajari pengaruh berbagai faktor(kombinasinya, kombinasinya) pada atribut efektif.
Inti dari metode analisis faktor adalah untuk mengecualikan deskripsi berbagai karakteristik yang dipelajari dan menggantinya dengan sejumlah kecil variabel yang secara informasi lebih luas, yang disebut faktor dan mencerminkan sifat fenomena yang paling signifikan. Variabel tersebut adalah beberapa fungsi dari fitur aslinya.
Analisis, dalam kata Ya.Okun, 9 memungkinkan untuk memiliki karakteristik perkiraan pertama dari keteraturan yang mendasari fenomena tersebut, untuk merumuskan kesimpulan umum pertama tentang arah di mana penelitian lebih lanjut harus dilakukan. Selanjutnya, ia menunjuk pada asumsi utama analisis faktor, yaitu bahwa fenomena tersebut, terlepas dari heterogenitas dan variabilitasnya, dapat dijelaskan oleh sejumlah kecil unit fungsional, parameter, atau faktor. Istilah-istilah ini disebut berbeda: pengaruh, penyebab, parameter, unit fungsional, kemampuan, indikator utama atau independen. Penggunaan satu istilah atau lainnya tunduk pada
Okun Ya.Analisis faktor: Per. Dengan. lantai. M.: Statistik, 1974.- P.16.
konteks tentang faktor dan pengetahuan tentang esensi dari fenomena yang diteliti.
Tahapan analisis faktor adalah perbandingan berurutan dari berbagai rangkaian faktor dan opsi untuk kelompok dengan inklusi, eksklusi, dan penilaian signifikansi perbedaan antar kelompok.
V.M. Zhukovska dan I.B. Muchnik 10, berbicara tentang inti dari tugas analisis faktor, berpendapat bahwa yang terakhir tidak memerlukan pembagian apriori variabel menjadi variabel dependen dan independen, karena semua variabel di dalamnya dianggap sama.
Tugas analisis faktor direduksi menjadi konsep tertentu, jumlah dan sifat dari karakteristik fungsional fenomena yang paling signifikan dan relatif independen, meter atau parameter dasarnya - faktor. Menurut penulis, ini penting ciri khas analisis faktor adalah memungkinkan Anda untuk secara bersamaan menjelajahi sejumlah besar variabel yang saling terkait tanpa asumsi "keteguhan semua kondisi lain", sangat diperlukan saat menggunakan sejumlah metode analisis lainnya. Ini adalah keuntungan besar dari analisis faktor sebagai alat yang berharga untuk mempelajari fenomena tersebut, karena keragaman yang kompleks dan jalinan hubungan.
Analisis bergantung terutama pada pengamatan variasi alami variabel.
1. Saat menggunakan analisis faktor, kumpulan variabel yang dipelajari dalam kaitannya dengan hubungan di antara mereka tidak dipilih secara sembarangan: metode ini memungkinkan Anda untuk mengidentifikasi faktor utama yang berdampak signifikan di bidang ini.
2. Analisis tidak memerlukan hipotesis pendahuluan, sebaliknya analisis itu sendiri dapat berfungsi sebagai metode untuk mengajukan hipotesis, serta bertindak sebagai kriteria hipotesis berdasarkan data yang diperoleh dengan metode lain.
3. Analisis tidak memerlukan tebakan apriori tentang variabel mana yang independen dan dependen, tidak melebih-lebihkan hubungan sebab akibat dan menyelesaikan masalah sejauh mana mereka dalam proses penelitian lebih lanjut.
Daftar tugas khusus yang harus diselesaikan dengan menggunakan metode analisis faktor adalah sebagai berikut (menurut V.M. Zhukovsky). Mari kita sebutkan yang utama di bidang penelitian sosial-ekonomi:
Zhukovskaya V.M., Muchnik I.B. Analisis faktor dalam penelitian sosial ekonomi. - Statistik, 1976. P.4.
1. Penentuan aspek-aspek utama perbedaan objek pengamatan (minimisasi deskripsi).
2. Perumusan hipotesis tentang sifat perbedaan antar objek.
3. Identifikasi struktur hubungan antar fitur.
4. Menguji hipotesis tentang hubungan dan pertukaran fitur.
5. Perbandingan struktur set fitur.
6. Pemutusan objek pengamatan untuk ciri khas.
Hal tersebut di atas menunjukkan kemungkinan besar analisis faktor di
studi tentang fenomena sosial, di mana, sebagai suatu peraturan, tidak mungkin untuk mengontrol (secara eksperimental) pengaruh faktor individu.
Penggunaan hasil analisis faktor dalam model regresi berganda cukup efektif.
Memiliki model korelasi-regresi yang telah dibentuk sebelumnya dari fenomena yang diteliti dalam bentuk fitur yang berkorelasi, dengan bantuan analisis faktor, sekumpulan fitur tersebut dapat diubah menjadi jumlah yang jauh lebih kecil dengan agregasi. Pada saat yang sama, perlu dicatat bahwa transformasi semacam itu sama sekali tidak merusak kualitas dan kelengkapan informasi tentang fenomena yang diteliti. Fitur agregat yang dihasilkan tidak berkorelasi dan mewakili kombinasi linear dari fitur utama. Dari sisi matematis formal, pernyataan masalah dalam hal ini dapat memiliki himpunan penyelesaian yang tak terhingga. Tetapi kita harus ingat bahwa ketika mempelajari fenomena sosial-ekonomi, tanda-tanda agregat yang diperoleh harus memiliki interpretasi yang dapat dibenarkan secara ekonomi. Dengan kata lain, dalam hal apa pun menggunakan peralatan matematika, pertama-tama, mereka keluar dari pengetahuan tentang esensi ekonomi dari fenomena yang dipelajari.
Dengan demikian, hal di atas memungkinkan kita untuk meringkas bahwa analisis faktor adalah metode penelitian khusus yang dilakukan berdasarkan gudang metode statistik matematika.
Analisis faktor pertama kali menemukan aplikasi praktisnya di bidang psikologi. Kemampuan untuk mereduksi sejumlah besar tes psikologi menjadi sejumlah kecil faktor memungkinkan untuk menjelaskan kemampuan kecerdasan manusia.
Dalam studi fenomena sosio-ekonomi, di mana terdapat kesulitan dalam mengisolasi pengaruh variabel individu, analisis faktor dapat digunakan dengan sukses. Penggunaan metodenya memungkinkan, melalui perhitungan tertentu, untuk "menyaring" ciri-ciri yang tidak penting dan melanjutkan penelitian ke arah pendalamannya.
Efektivitas metode ini terlihat jelas dalam mempelajari masalah (masalah) seperti itu: dalam ekonomi - spesialisasi dan konsentrasi produksi, intensitas rumah tangga, anggaran keluarga pekerja, pembangunan berbagai indikator generalisasi. dll.
ANALISIS STATISTIK MULTIVARIAT
Bagian Matematika. statistik, didedikasikan untuk matematika. metode membangun rencana optimal untuk pengumpulan, sistematisasi, dan pemrosesan statistik multidimensi. data yang bertujuan untuk mengidentifikasi sifat dan struktur hubungan antara komponen sifat multidimensi yang dipelajari dan dimaksudkan untuk memperoleh ilmiah dan praktis. kesimpulan. Atribut multidimensi dipahami sebagai indikator p-dimensi (fitur, variabel), di antaranya dapat berupa: mengurutkan objek yang dianalisis sesuai dengan tingkat manifestasi properti yang dipelajari di dalamnya; dan klasifikasi (atau nominal), yaitu, memungkinkan untuk membagi kumpulan objek yang dipelajari ke dalam kelas-kelas yang tidak dapat diatur secara homogen (menurut properti yang dianalisis). Hasil pengukuran indikator tersebut
pada setiap objek populasi yang diteliti, mereka membentuk pengamatan multidimensi, atau larik awal data multidimensi untuk melakukan M. s. sebuah. Bagian penting dari M. s. sebuah. Melayani situasi di mana fitur multidimensi yang dipelajari ditafsirkan sebagai multidimensi dan, karenanya, urutan pengamatan multidimensi (1) - seperti dari populasi umum. Dalam hal ini, pilihan metode untuk memproses statistik asli. data dan analisis propertinya didasarkan pada asumsi tertentu mengenai sifat hukum distribusi probabilitas multidimensi (gabungan).
Analisis statistik multivariat dari distribusi multivariat dan karakteristik utamanya hanya mencakup situasi di mana pengamatan (1) yang sedang diproses bersifat probabilistik, yaitu, mereka ditafsirkan sebagai sampel dari populasi umum yang sesuai. Tugas pokok subbagian ini meliputi: statistik. estimasi distribusi multivariat yang dipelajari, karakteristik dan parameter numerik utamanya; mempelajari sifat-sifat statistik yang digunakan. peringkat; studi tentang distribusi probabilitas untuk sejumlah statistik, dengan bantuan data statistik yang dibangun. kriteria untuk menguji berbagai hipotesis tentang sifat probabilistik dari data multivariat yang dianalisis. Hasil utama berhubungan dengan kasus tertentu ketika fitur yang diteliti tunduk pada hukum distribusi normal multidimensi, yang fungsi kerapatannya diberikan oleh relasi

dimana adalah vektor matematika. harapan komponen variabel acak , yaitu ![]() adalah matriks kovarians dari vektor acak , yaitu kovarians komponen vektor (kami mempertimbangkan kasus non-degenerasi ketika ; jika tidak, yaitu untuk peringkat , semua hasil tetap valid, tetapi diterapkan pada subruang dengan dimensi lebih rendah , di mana ternyata terkonsentrasi vektor acak yang diteliti).
adalah matriks kovarians dari vektor acak , yaitu kovarians komponen vektor (kami mempertimbangkan kasus non-degenerasi ketika ; jika tidak, yaitu untuk peringkat , semua hasil tetap valid, tetapi diterapkan pada subruang dengan dimensi lebih rendah , di mana ternyata terkonsentrasi vektor acak yang diteliti).
Jadi, jika (1) adalah urutan pengamatan independen yang membentuk sampel acak dari maka perkiraan kemungkinan maksimum untuk parameter dan berpartisipasi dalam (2) masing-masing adalah statistik (lihat , )
di mana vektor acak mematuhi hukum normal dimensi-p ![]() dan tidak bergantung pada , dan distribusi bersama elemen matriks dijelaskan oleh apa yang disebut Distribusi keinginan r-t a (lihat), to-rogo
dan tidak bergantung pada , dan distribusi bersama elemen matriks dijelaskan oleh apa yang disebut Distribusi keinginan r-t a (lihat), to-rogo

Dalam kerangka skema yang sama, distribusi dan momen karakteristik sampel seperti variabel acak multidimensi sebagai koefisien pasangan, korelasi parsial dan ganda, digeneralisasikan (yaitu ), statistik Hotelling umum (lihat ). Secara khusus (lihat ), jika kita mendefinisikan matriks kovarian sampel sebagai estimasi yang dikoreksi "untuk ketidakberpihakan", yaitu:
kemudian variabel acak ![]() cenderung sebagai , dan variabel acak
cenderung sebagai , dan variabel acak

mematuhi distribusi-F dengan jumlah derajat kebebasan masing-masing (p, n-p) dan (p, n 1 + n 2-p-1). Sehubungan (7) hal 1 dan n 2 - volume dua sampel independen dari bentuk (1), diambil dari populasi umum yang sama - perkiraan bentuk (3) dan (4)-(5), dibangun di atas sampel ke-i, dan
Total sampel kovarians , dibangun dari perkiraan dan
Analisis statistik multivariat dari sifat dan struktur keterkaitan komponen sifat multidimensi yang diteliti menggabungkan konsep dan hasil yang melayani metode dan model M. s. a., sebagai jamak, multidimensi analisis varian dan analisis kovarians, analisis faktor dan analisis komponen utama, analisis kanonik. korelasi. Hasil yang membentuk isi subbagian ini secara kasar dapat dibagi menjadi dua jenis utama.
1) Konstruksi statistik terbaik (dalam arti tertentu). estimasi untuk parameter model yang disebutkan dan analisis propertinya (akurasi, dan dalam pengaturan probabilistik - hukum distribusinya, kepercayaan: area, dll.). Jadi, biarkan fitur multivariat yang diteliti diinterpretasikan sebagai vektor acak , tunduk pada distribusi normal p-dimensi , dan dibagi menjadi dua subvektor - kolom dan dimensi q dan p-q, masing-masing. Ini juga menentukan pembagian yang sesuai dari vektor matematika. ekspektasi, matriks kovarian teoritis dan sampel, yaitu:
Kemudian (lihat , ) subvektor (dengan asumsi bahwa subvektor kedua telah mengambil nilai tetap ) juga akan menjadi normal ). Dalam hal ini, perkiraan kemungkinan maksimum. untuk matriks koefisien regresi dan kovarian model regresi berganda multivariat klasik ini
akan ada statistik yang saling independen, masing-masing
di sini distribusi estimasi tunduk pada hukum normal ![]() , dan perkirakan n - ke hukum Wishart dengan parameter dan (elemen matriks kovarian dinyatakan dalam bentuk elemen matriks ).
, dan perkirakan n - ke hukum Wishart dengan parameter dan (elemen matriks kovarian dinyatakan dalam bentuk elemen matriks ).
Hasil utama pada konstruksi estimasi parameter dan studi propertinya dalam model analisis faktorial, komponen utama dan korelasi kanonik terkait dengan analisis properti statistik probabilistik dari nilai eigen dan vektor dari berbagai matriks kovarians sampel.
Dalam skema yang tidak sesuai dengan kerangka klasik. model normal, dan terlebih lagi dalam kerangka model probabilistik apa pun, hasil utama terkait dengan konstruksi algoritme (dan studi tentang propertinya) untuk menghitung estimasi parameter yang terbaik dari sudut pandang beberapa kualitas yang diberikan secara eksogen ( atau kecukupan) fungsional model.
2) Konstruksi statistik. kriteria untuk menguji berbagai hipotesis tentang struktur hubungan yang dipelajari. Dalam kerangka model normal multivariat (urutan pengamatan bentuk (1) ditafsirkan sebagai sampel acak dari populasi umum normal multivariat yang sesuai), misalnya, data statistik dibangun. kriteria untuk menguji hipotesis berikut.
I. Hipotesis tentang persamaan matematika vektor. ekspektasi dari indikator yang dipelajari terhadap vektor spesifik yang diberikan; diverifikasi menggunakan Hotelling -statistics dengan substitusi pada rumus (6)
II. Hipotesis tentang kesetaraan vektor matematika. harapan dalam dua populasi (dengan matriks kovarians yang sama tetapi tidak diketahui) diwakili oleh dua sampel; diverifikasi menggunakan statistik (lihat ).
AKU AKU AKU. Hipotesis tentang kesetaraan vektor matematika. harapan dalam beberapa populasi umum (dengan matriks kovarians yang sama tetapi tidak diketahui) diwakili oleh sampel mereka; diverifikasi dengan statistik
di mana ada dimensi-p ke-i pengamatan dalam volume sampel yang mewakili jenderal j-th himpunan, dan dan adalah taksiran dari bentuk (3), masing-masing dibangun secara terpisah untuk masing-masing sampel dan untuk sampel volume gabungan
IV. Hipotesis tentang kesetaraan beberapa populasi normal yang diwakili oleh sampelnya diverifikasi menggunakan statistik

di mana - perkiraan bentuk (4), dibuat terpisah dari pengamatan j- sampel, j=1, 2, ... , k.
V. Hipotesis tentang independensi timbal balik dari subvektor-kolom dimensi, masing-masing, di mana vektor dimensi-p asli dari indikator yang dipelajari dibagi diperiksa menggunakan statistik

di mana dan adalah matriks kovarians sampel dari bentuk (4) untuk seluruh vektor dan untuk subvektornya x(i) masing-masing.
Analisis statistik multivariat dari struktur geometris dari rangkaian pengamatan multivariat yang dipelajari menggabungkan konsep dan hasil dari model dan skema seperti analisis diskriminan, campuran distribusi probabilitas, analisis klaster dan taksonomi, penskalaan multivariat. Nodal dalam semua skema ini adalah konsep jarak (ukuran kedekatan, ukuran kesamaan) antara elemen yang dianalisis. Pada saat yang sama, mereka dapat dianalisis sebagai objek nyata, yang masing-masing nilai indikatornya ditetapkan - kemudian geometris. gambar objek ke-i yang disurvei akan menjadi titik dalam ruang dimensi-p yang sesuai, dan indikatornya sendiri - kemudian geometris. gambar indeks ke-l akan menjadi titik dalam ruang n-dimensi yang sesuai.
Metode dan hasil analisis diskriminan (lihat , , ) ditujukan untuk tugas-tugas berikut. Diketahui bahwa ada sejumlah populasi tertentu, dan peneliti memiliki satu sampel dari setiap populasi ("sampel pelatihan"). Diperlukan untuk membangun aturan klasifikasi terbaik berdasarkan sampel pelatihan yang tersedia dalam arti tertentu, yang memungkinkan seseorang untuk menetapkan elemen baru tertentu (pengamatan ) ke populasi umumnya dalam situasi di mana peneliti tidak mengetahui sebelumnya yang mana dari populasi elemen ini milik. Biasanya, aturan klasifikasi dipahami sebagai urutan tindakan: dengan menghitung fungsi skalar dari indikator yang diteliti, menurut nilainya, keputusan dibuat untuk menetapkan elemen ke salah satu kelas (konstruksi a fungsi diskriminan); mengurutkan indikator itu sendiri sesuai dengan tingkat keinformatifannya dari sudut pandang penugasan elemen yang benar ke kelas; dengan menghitung probabilitas kesalahan klasifikasi yang sesuai.
Masalah menganalisis campuran distribusi probabilitas (lihat ) paling sering (tetapi tidak selalu) juga muncul sehubungan dengan studi tentang "struktur geometris" populasi yang sedang dipertimbangkan. Dalam hal ini, konsep kelas homogen ke-r diformalkan dengan bantuan populasi umum yang dijelaskan oleh beberapa hukum distribusi (biasanya unimodal) sehingga distribusi populasi umum, dari mana sampel (1) diekstraksi, dijelaskan oleh campuran distribusi bentuk di mana p r - probabilitas apriori (elemen spesifik) dari kelas ke-r dalam populasi umum. Tugasnya adalah memiliki statistik yang "baik". estimasi (berdasarkan sampel) parameter yang tidak diketahui dan terkadang ke. Hal ini, khususnya, memungkinkan untuk mengurangi masalah pengklasifikasian elemen menjadi skema analisis diskriminan, meskipun dalam hal ini tidak ada sampel pelatihan.
Metode dan hasil analisis klaster (klasifikasi, taksonomi, pengenalan pola "tanpa guru", lihat , , ) ditujukan untuk memecahkan masalah berikut. Geometris dari kumpulan elemen yang dianalisis diberikan baik oleh koordinat titik-titik yang sesuai (yaitu, oleh matriks ... , n) , atau satu set geometris karakteristik posisi relatif mereka, misalnya, dengan matriks jarak berpasangan . Himpunan elemen yang dipelajari harus dibagi menjadi kelas yang relatif kecil (diketahui sebelumnya atau tidak) sehingga elemen dari satu kelas berada pada jarak yang kecil satu sama lain, sementara kelas yang berbeda, jika mungkin, cukup saling menguntungkan. jauh dari satu sama lain dan tidak akan dibagi menjadi bagian-bagian yang jauh dari satu sama lain.
Masalah penskalaan multidimensi (lihat ) mengacu pada situasi di mana himpunan elemen yang diteliti ditentukan menggunakan matriks jarak berpasangan dan terdiri dari menetapkan sejumlah koordinat (p) tertentu ke masing-masing elemen sedemikian rupa sehingga struktur jarak timbal balik berpasangan antara elemen yang diukur menggunakan koordinat tambahan ini, rata-rata, akan menjadi yang paling tidak berbeda dari yang diberikan. Perlu dicatat bahwa hasil utama dan metode analisis klaster dan penskalaan multidimensi biasanya dikembangkan tanpa asumsi tentang sifat probabilistik dari data awal.
Tujuan penerapan analisis statistik multivariat terutama untuk melayani tiga masalah berikut.
Masalah penelitian statistik ketergantungan antara indikator yang dianalisis. Dengan asumsi bahwa kumpulan indikator x yang direkam secara statistik dibagi, berdasarkan makna yang berarti dari indikator ini dan tujuan akhir penelitian, menjadi subvektor dimensi-q dari variabel prediktif (tergantung) dan subvektor dimensi-p (p-q) dari variabel prediktif (independen), kita dapat mengatakan bahwa masalahnya adalah untuk menentukan, berdasarkan sampel (1), fungsi vektor dimensi-q dari kelas solusi yang dapat diterima F, akan memberikan yang terbaik, dalam arti tertentu, perkiraan perilaku subvektor indikator . Bergantung pada jenis spesifik dari fungsi kualitas pendekatan dan sifat indikator yang dianalisis, mereka sampai pada satu atau beberapa skema regresi berganda, dispersi, kovarians atau analisis konfluen.
Masalah mengklasifikasikan elemen (objek atau indikator) dalam formulasi umum (tidak ketat) adalah membagi seluruh rangkaian elemen yang dianalisis, disajikan secara statistik dalam bentuk matriks atau matriks, menjadi sejumlah kecil yang homogen, dalam pengertian tertentu, kelompok. Bergantung pada sifat informasi apriori dan jenis fungsional spesifik yang menetapkan kriteria kualitas klasifikasi, satu atau beberapa skema analisis diskriminan, analisis kluster (taksonomi, pengenalan pola "tanpa pengawasan"), pemisahan campuran distribusi terjadi.
Masalah pengurangan dimensi ruang faktor yang diteliti dan pemilihan indikator yang paling informatif adalah untuk menentukan sekumpulan indikator yang jumlahnya relatif kecil yang ditemukan di kelas transformasi yang dapat diterima dari indikator aslinya. ![]() pada Krom, ukuran tertentu yang diberikan secara eksogen atas konten informasi dari sistem fitur m-dimensi tercapai (lihat ). Spesifikasi fungsional yang menetapkan ukuran autoinformatif (yaitu, ditujukan untuk pelestarian maksimum informasi yang terkandung dalam susunan statistik (1) relatif terhadap fitur asli itu sendiri), mengarah, khususnya, ke berbagai skema analisis faktor dan prinsip. komponen, hingga metode pengelompokan fitur yang ekstrem . Fungsional yang menentukan ukuran konten informasi eksternal, yaitu, ditujukan untuk mengekstraksi dari (1) informasi maksimum mengenai beberapa informasi lain yang tidak terkandung langsung dalam w, indikatif atau fenomena, mengarah pada berbagai metode untuk memilih indikator yang paling informatif dalam skema statistik. studi ketergantungan dan analisis diskriminan.
pada Krom, ukuran tertentu yang diberikan secara eksogen atas konten informasi dari sistem fitur m-dimensi tercapai (lihat ). Spesifikasi fungsional yang menetapkan ukuran autoinformatif (yaitu, ditujukan untuk pelestarian maksimum informasi yang terkandung dalam susunan statistik (1) relatif terhadap fitur asli itu sendiri), mengarah, khususnya, ke berbagai skema analisis faktor dan prinsip. komponen, hingga metode pengelompokan fitur yang ekstrem . Fungsional yang menentukan ukuran konten informasi eksternal, yaitu, ditujukan untuk mengekstraksi dari (1) informasi maksimum mengenai beberapa informasi lain yang tidak terkandung langsung dalam w, indikatif atau fenomena, mengarah pada berbagai metode untuk memilih indikator yang paling informatif dalam skema statistik. studi ketergantungan dan analisis diskriminan.
Alat matematika utama M. s. sebuah. merupakan metode khusus dari teori sistem persamaan linear dan teori matriks (metode untuk memecahkan masalah sederhana dan umum dari nilai eigen dan vektor; inversi sederhana dan pseudo-inversi matriks; prosedur diagonalisasi matriks, dll.) dan algoritma pengoptimalan tertentu (metode penurunan koordinat, gradien konjugasi, cabang dan batasan, berbagai versi pencarian acak dan perkiraan stokastik, dll.).
Menyala.: Anderson T., Pengantar analisis statistik multivariat, trans. dari bahasa Inggris, M., 1963; Kendall M.J., Stewart A., Analisis statistik multivariat dan deret waktu, trans. dari bahasa Inggris, M., 1976; Bolshev L.N., "Bull. Int. Stat. Inst.", 1969, No. 43, hal. 425-41; Wishart.J., "Biometrika", 1928, v. 20A, hal. 32-52: Hotelling H., "Ann. Math. Stat.", 1931, v. 2, hal. 360-78; [c] Kruskal J.V., "Psychometrika", 1964, v. 29, hal. 1-27; Ayvazyan S.A., Bezhaeva Z.I., . Staroverov O. V., Klasifikasi pengamatan multidimensi, M., 1974.
S.A. Ayvazyan.
Ensiklopedia matematika. - M.: Ensiklopedia Soviet. I.M. Vinogradov. 1977-1985.
Buku Panduan Penerjemah TeknisBagian statistik matematika (lihat), dikhususkan untuk matematika. metode yang ditujukan untuk mengidentifikasi sifat dan struktur hubungan antara komponen fitur multidimensi yang dipelajari (lihat) dan dimaksudkan untuk memperoleh ilmiah. dan praktis……
Dalam arti luas, bagian statistik matematika (Lihat Statistik Matematika), yang menggabungkan metode untuk mempelajari data statistik yang terkait dengan objek yang dicirikan oleh beberapa ... ... Ensiklopedia Soviet yang Hebat
ANALISIS STATISTIK MULTIVARIAT- bagian statistik matematika yang dirancang untuk menganalisis hubungan antara tiga variabel atau lebih. Secara kondisional kita dapat membedakan tiga kelas utama A.M.S. Ini adalah studi tentang struktur hubungan antar variabel dan pengurangan dimensi ruang ... Sosiologi: Ensiklopedia
ANALISIS KOVARIANSI- - satu set metode matematika. statistik yang terkait dengan analisis model ketergantungan nilai rata-rata variabel acak tertentu Y pada sekumpulan faktor non-kuantitatif F dan pada saat yang sama pada sekumpulan faktor kuantitatif X. Sehubungan dengan Y ... . .. Ensiklopedia sosiologi Rusia
Bagian Matematika. statistika yang isinya adalah pengembangan dan kajian ilmu statistika. metode untuk memecahkan masalah diskriminasi (diskriminasi) berikut: berdasarkan hasil pengamatan, tentukan yang mana dari beberapa kemungkinan ... ... Ensiklopedia Matematika, Orlova Irina Vladlenovna, Kontsevaya Natalya Valerievna, Turundaevsky Viktor Borisovich. Buku ini dikhususkan untuk analisis statistik multivariat (MSA) dan organisasi perhitungan menurut MSA. Untuk mengimplementasikan metode statistik multivariat, digunakan program pengolah statistik ...
Analisis statistik multivariat digunakan untuk memecahkan masalah berikut:
- * studi tentang hubungan antara fitur;
- * klasifikasi objek atau fitur yang diberikan oleh vektor;
- * pengurangan dimensi ruang fitur.
Dalam hal ini, hasil pengamatan adalah vektor nilai dari sejumlah tetap fitur kuantitatif dan terkadang kualitatif yang diukur dalam suatu objek. Tanda kuantitatif adalah tanda dari satuan yang diamati, yang dapat langsung dinyatakan dengan angka dan satuan ukuran. Atribut kuantitatif berlawanan dengan atribut kualitatif - atribut dari unit yang diamati, ditentukan dengan penugasan ke salah satu dari dua atau lebih kategori bersyarat (jika hanya ada dua kategori, maka atribut tersebut disebut alternatif). Analisis statistik fitur kualitatif adalah bagian dari statistik objek non-numerik. Tanda-tanda kuantitatif dibagi menjadi tanda-tanda yang diukur dalam skala interval, rasio, perbedaan, absolut.
Dan kualitatif - pada tanda-tanda yang diukur dalam skala nama dan skala ordinal. Metode pemrosesan data harus konsisten dengan skala di mana karakteristik yang dipertimbangkan diukur.
Tujuan mempelajari hubungan antar fitur adalah untuk membuktikan adanya hubungan antar fitur dan untuk mempelajari hubungan tersebut. Analisis korelasi digunakan untuk membuktikan adanya hubungan antara dua variabel acak X dan Y. Jika distribusi gabungan dari X dan Y normal, maka inferensi statistik didasarkan pada sampel koefisien korelasi linier, dalam kasus lain, koefisien korelasi peringkat Kendall dan Spearman digunakan, dan untuk fitur kualitatif, uji chi-square digunakan .
Analisis regresi digunakan untuk mempelajari ketergantungan fungsional sifat kuantitatif Y terhadap sifat kuantitatif x(1), x(2), ..., x(k). Ketergantungan ini disebut regresi atau singkatnya regresi. Model analisis regresi probabilistik yang paling sederhana (dalam kasus k = 1) menggunakan sebagai informasi awal sekumpulan pasangan hasil pengamatan (xi, yi), i = 1, 2, … , n, dan berbentuk
yi = sumbu + b + ei, i = 1, 2, … , n,
di mana ei adalah kesalahan pengamatan. Kadang-kadang diasumsikan bahwa ei adalah variabel acak bebas dengan distribusi normal yang sama N(0, y2). Karena distribusi kesalahan pengamatan biasanya berbeda dari normal, disarankan untuk mempertimbangkan model regresi dalam formulasi nonparametrik, yaitu untuk sewenang-wenang distribusi ei.
Tugas utama analisis regresi adalah memperkirakan parameter yang tidak diketahui a dan b, yang menentukan ketergantungan linier y pada x. Untuk mengatasi masalah ini digunakan metode kuadrat terkecil yang dikembangkan oleh K. Gauss pada tahun 1794, yaitu temukan estimasi parameter model yang tidak diketahui a dan b dari kondisi meminimalkan jumlah kuadrat
untuk variabel a dan b.
Analisis varians digunakan untuk mempelajari pengaruh fitur kualitatif terhadap variabel kuantitatif. Misal ada k sampel hasil pengukuran indikator kuantitatif kualitas unit produksi yang diproduksi pada k mesin, yaitu sekumpulan angka (x1(j), x2(j), … , xn(j)), di mana j adalah nomor mesin, j = 1, 2, …, k, dan n adalah ukuran sampel. Dalam rumusan umum analisis varian, diasumsikan bahwa hasil pengukuran bersifat independen dan pada setiap sampel berdistribusi normal N(m(j), y2) dengan varian yang sama.
Pengecekan keseragaman mutu produk, yaitu kurangnya pengaruh nomor mesin pada kualitas produk, bermuara pada pengujian hipotesis
H0: m(1) = m(2) = … = m(k).
Dalam analisis dispersi, metode untuk menguji hipotesis semacam itu telah dikembangkan.
Hipotesis H0 diuji terhadap hipotesis alternatif H1, yang menurutnya setidaknya salah satu persamaan yang ditunjukkan tidak terpenuhi. Verifikasi hipotesis ini didasarkan pada "dekomposisi varians" berikut yang ditunjukkan oleh R.A. Fisher:
di mana s2 adalah varians sampel dalam sampel gabungan, yaitu
Jadi, suku pertama di sisi kanan rumus (7) mencerminkan dispersi intragrup. Akhirnya, varians antarkelompok,
Area statistik terapan yang terkait dengan perluasan varian dari jenis rumus (7) disebut analisis varian. Sebagai contoh masalah analisis varian, pertimbangkan untuk menguji hipotesis H0 di atas dengan asumsi bahwa hasil pengukuran bersifat independen dan pada setiap sampel berdistribusi normal N(m(j), y2) dengan varian yang sama. Jika H0 benar, suku pertama di sebelah kanan rumus (7), dibagi dengan y2, memiliki distribusi khi-kuadrat dengan k(n-1) derajat kebebasan, dan suku kedua, dibagi dengan y2, juga memiliki distribusi chi-kuadrat, tetapi dengan derajat kebebasan ( k-1), dan suku pertama dan kedua bebas sebagai variabel acak. Jadi variabel acak

memiliki distribusi Fisher dengan (k-1) derajat kebebasan pembilang dan k(n-1) derajat kebebasan penyebut. Hipotesis H0 diterima jika F< F1-б, и отвергается в противном случае, где F1-б - квантиль порядка 1-б распределения Фишера с указанными числами степеней свободы. Такой выбор критической области определяется тем, что при Н1 величина F безгранично увеличивается при росте объема выборок n. Значения F1-б берут из соответствующих таблиц.
Metode nonparametrik untuk memecahkan masalah klasik analisis dispersi, khususnya pengujian hipotesis H0, telah dikembangkan.
Jenis masalah analisis statistik multivariat selanjutnya adalah masalah klasifikasi. Mereka pada dasarnya dibagi menjadi tiga berbeda jenis- analisis diskriminan, analisis klaster, pengelompokan masalah.
Tugas analisis diskriminan adalah menemukan aturan untuk menugaskan objek yang diamati ke salah satu kelas yang dijelaskan sebelumnya. Dalam hal ini, objek dideskripsikan dalam model matematika dengan menggunakan vektor yang koordinatnya merupakan hasil pengamatan sejumlah fitur dari setiap objek. Kelas dijelaskan baik secara langsung dalam istilah matematika atau menggunakan sampel pelatihan. Sampel pelatihan adalah sampel, untuk setiap elemen yang ditunjukkan ke kelas mana ia berasal.
Pertimbangkan contoh penerapan analisis diskriminan untuk pengambilan keputusan dalam diagnostik teknis. Biarlah perlu untuk menetapkan ada atau tidaknya cacat berdasarkan hasil pengukuran sejumlah parameter produk. Dalam hal ini, untuk elemen sampel pelatihan, cacat yang ditemukan selama studi tambahan, misalnya, dilakukan setelah periode operasi tertentu, ditunjukkan. Analisis diskriminan memungkinkan Anda mengurangi jumlah kontrol, serta memprediksi perilaku produk di masa mendatang. Analisis diskriminan mirip dengan regresi - yang pertama memungkinkan Anda memprediksi nilai sifat kualitatif, dan yang kedua - kuantitatif. Dalam statistik objek yang bersifat non-numerik, skema matematika telah dikembangkan, kasus khususnya adalah analisis regresi dan diskriminan.
Analisis klaster digunakan ketika, menurut data statistik, elemen sampel perlu dibagi menjadi beberapa kelompok. Selain itu, dua elemen kelompok dari kelompok yang sama harus "dekat" dalam hal totalitas nilai karakteristik yang diukur di dalamnya, dan dua elemen dari kelompok yang berbeda harus "jauh" dalam arti yang sama. Berbeda dengan analisis diskriminan, dalam analisis cluster, kelas tidak ditentukan, tetapi dibentuk dalam proses pengolahan data statistik. Sebagai contoh, analisis klaster dapat digunakan untuk memecah satu set nilai baja (atau nilai kulkas) menjadi kelompok serupa.
Jenis lain dari analisis klaster adalah pembagian fitur ke dalam kelompok yang serupa. Koefisien korelasi sampel dapat berfungsi sebagai indikator kesamaan fitur. Tujuan dari analisis klaster fitur adalah untuk mengurangi jumlah parameter yang dikontrol, yang secara signifikan dapat mengurangi biaya kontrol. Untuk melakukan ini, dari sekelompok tanda yang terkait erat (yang koefisien korelasinya mendekati 1 - nilai maksimumnya), nilai satu diukur, dan nilai sisanya dihitung menggunakan analisis regresi.
Masalah pengelompokan diselesaikan ketika kelas tidak ditentukan sebelumnya dan tidak harus "jauh" dari satu sama lain. Contohnya adalah pengelompokan siswa ke dalam kelompok belajar. Dalam teknologi, solusi untuk masalah pengelompokan seringkali berupa deret parametrik - ukuran yang mungkin dikelompokkan menurut elemen deret parametrik. Dalam literatur, dokumen normatif-teknis dan instruktif-metodis tentang statistik terapan, pengelompokan hasil pengamatan juga kadang-kadang digunakan (misalnya, saat membuat histogram).
Masalah klasifikasi diselesaikan tidak hanya dalam analisis statistik multivariat, tetapi juga ketika hasil pengamatan berupa angka, fungsi, atau objek non-numerik. Jadi, banyak algoritma analisis cluster hanya menggunakan jarak antar objek. Oleh karena itu, mereka juga dapat digunakan untuk mengklasifikasikan objek yang bersifat non-numerik, asalkan jarak antara mereka diberikan. Masalah klasifikasi paling sederhana adalah sebagai berikut: diberikan dua sampel independen, diperlukan untuk menentukan apakah mereka mewakili dua kelas atau satu. Dalam statistik satu dimensi, masalah ini direduksi menjadi pengujian hipotesis homogenitas.
Bagian ketiga dari analisis statistik multivariat adalah masalah reduksi dimensi (kompresi informasi). Tujuan dari solusi mereka adalah untuk menentukan kumpulan indikator turunan yang diperoleh dengan mengubah fitur aslinya, sedemikian rupa sehingga jumlah indikator turunan secara signifikan lebih sedikit daripada jumlah fitur aslinya, tetapi mengandung sebanyak mungkin informasi yang tersedia. dalam data statistik asli. Masalah pengurangan dimensi diselesaikan dengan menggunakan penskalaan multidimensi, komponen utama, analisis faktor, dll. Misalnya, di model paling sederhana penskalaan multidimensi, data awal adalah jarak berpasangan antara k objek, dan tujuan perhitungannya adalah untuk merepresentasikan objek sebagai titik pada bidang. Ini memungkinkan untuk benar-benar melihat bagaimana objek berhubungan satu sama lain. Untuk mencapai tujuan ini, setiap objek perlu diberi titik pada bidang sehingga jarak berpasangan sij antara titik-titik yang sesuai dengan objek dengan angka i dan j mereproduksi jarak сij antara objek-objek ini seakurat mungkin. Menurut ide dasar metode kuadrat terkecil, titik-titik pada bidang dicari sehingga nilainya
mencapai nilai terendahnya. Ada banyak definisi masalah lain untuk reduksi dimensi dan visualisasi data.
kualitas statistik matematika probabilitas
Objek sosial dan ekonomi, pada umumnya, dicirikan oleh sejumlah besar parameter yang membentuk vektor multidimensi, dan masalah mempelajari hubungan antara komponen vektor ini sangat penting dalam studi ekonomi dan sosial, dan hubungan ini harus diidentifikasi berdasarkan sejumlah terbatas pengamatan multidimensi.
Analisis statistik multivariat adalah bagian dari statistik matematika yang mempelajari metode pengumpulan dan pemrosesan data statistik multivariat, sistematisasi dan pemrosesannya untuk mengidentifikasi sifat dan struktur hubungan antara komponen atribut multivariat yang dipelajari, dan untuk menarik kesimpulan praktis.
Perhatikan bahwa metode pengumpulan data dapat bervariasi. Jadi, jika penelitian ekonomi dunia, maka wajar untuk mengambil negara sebagai objek di mana nilai-nilai vektor X diamati, tetapi jika sistem ekonomi nasional sedang dipelajari, maka wajar untuk mengamati nilai-nilai vektor X di tempat yang sama. (menarik bagi peneliti) negara pada titik waktu yang berbeda.
Metode statistik seperti korelasi berganda dan analisis regresi secara tradisional dipelajari dalam kursus teori probabilitas dan statistik matematika, disiplin "Ekonometrika" dikhususkan untuk pertimbangan aspek terapan analisis regresi.
Manual ini dikhususkan untuk metode lain untuk mempelajari populasi umum multivariat berdasarkan data statistik.
Metode untuk mengurangi dimensi ruang multidimensi memungkinkan, tanpa kehilangan informasi yang signifikan, untuk berpindah dari sistem asli sejumlah besar faktor yang saling terkait yang diamati ke sistem dengan jumlah faktor tersembunyi (tidak dapat diamati) yang jauh lebih kecil yang menentukan variasi dari fitur awal. Bab pertama menjelaskan metode analisis komponen dan faktor, yang dapat digunakan untuk mengidentifikasi secara objektif ada, tetapi pola yang tidak dapat diamati secara langsung menggunakan komponen atau faktor utama.
Metode klasifikasi multidimensi dirancang untuk membagi koleksi objek (ditandai dengan sejumlah besar fitur) ke dalam kelas, yang masing-masing harus menyertakan objek yang homogen atau serupa dalam arti tertentu. Klasifikasi semacam itu berdasarkan data statistik pada nilai fitur pada objek dapat dilakukan dengan menggunakan metode analisis kluster dan diskriminan, yang dibahas di bab kedua (Analisis statistik multivariat menggunakan "STATISTIKA").
Perkembangan teknologi komputer dan perangkat lunak berkontribusi pada pengenalan luas metode analisis statistik multivariat ke dalam praktik. Paket aplikasi dengan antarmuka pengguna yang mudah digunakan, seperti SPSS, Statistica, SAS, dll., Menghilangkan kesulitan dalam menerapkan metode ini, yang merupakan kerumitan alat matematika berdasarkan aljabar linier, teori probabilitas dan statistik matematika, dan rumitnya perhitungan.
Namun, penggunaan program tanpa memahami esensi matematis dari algoritme yang digunakan berkontribusi pada pengembangan ilusi peneliti tentang kesederhanaan penggunaan metode statistik multivariat, yang dapat menyebabkan hasil yang salah atau tidak masuk akal. Hasil praktis yang signifikan hanya dapat diperoleh berdasarkan pengetahuan profesional di bidang subjek, didukung oleh pengetahuan tentang metode matematika dan paket aplikasi di mana metode ini diterapkan.
Oleh karena itu, untuk setiap metode yang dibahas dalam buku ini, diberikan informasi teori dasar, termasuk algoritme; implementasi metode dan algoritma ini dalam paket aplikasi dibahas. Metode yang dipertimbangkan diilustrasikan dengan contoh mereka aplikasi praktis di bidang ekonomi menggunakan paket SPSS.
Panduan ini ditulis berdasarkan pengalaman membaca kursus "Metode statistik multivariat" kepada siswa Universitas Negeri pengelolaan. Untuk studi yang lebih rinci tentang metode analisis statistik multivariat terapan, buku direkomendasikan.
Diasumsikan bahwa pembaca sangat mengenal mata kuliah aljabar linier (misalnya, dalam volume buku teks dan lampiran buku teks), teori probabilitas, dan statistik matematika (misalnya, dalam volume buku teks).